





How to Choose a Peptide Library for PhIP-Seq: Proteome-Wide, Pathogen-Focused, and Custom Designs
- Peptide Array-Based Epitope Mapping Service
- Peptide Epitope Substitution Scans Service
- Epitope Mapping Service
- Antibody-Antigen Interactions Characterization Service | HDX-MS
- Antibody-Antigen Complexes Structure Characterization Service
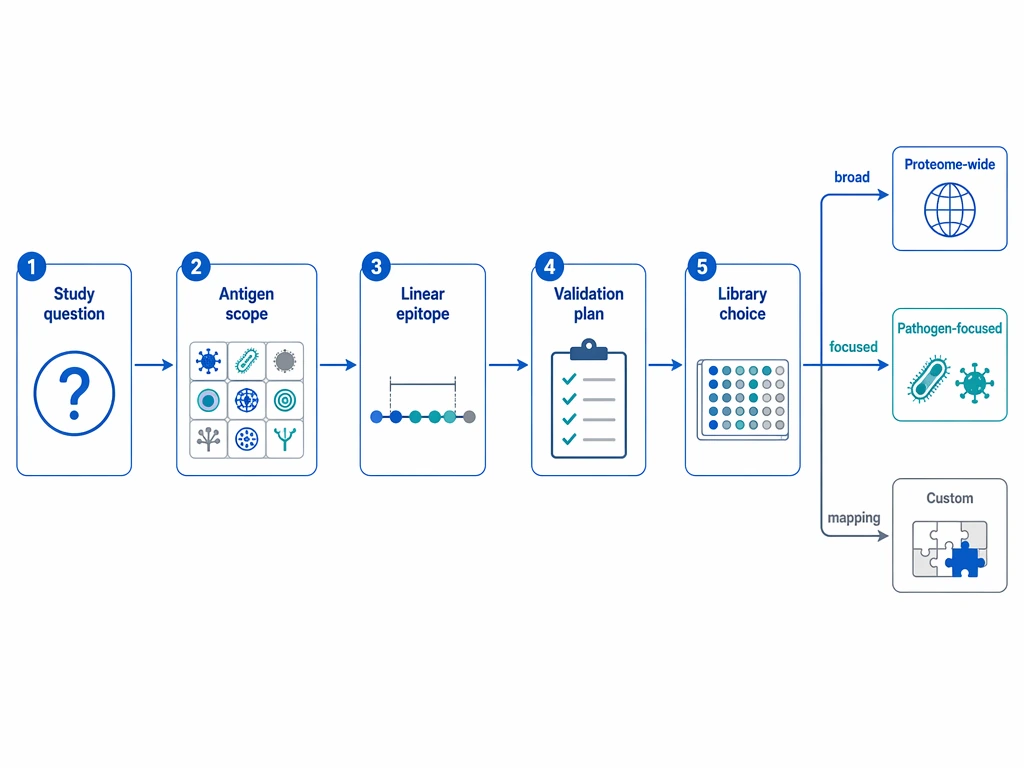
- Broad discovery: start with a proteome-wide library
- Defined pathogen profiling: prioritize a pathogen-focused library
- Focused antigen, variant, or mapping question: consider a custom peptide library
- Antigen coverage should match the biological scope of the question.
- Peptide length and tiling density should match the desired mapping resolution.
- Library complexity should match the available sequencing depth and analysis capacity.
- Sample input should match the number of planned screens, repeats, and confirmation assays.
- How many candidate hits can the team realistically confirm?
- Will follow-up use peptide arrays, substitution scans, or another peptide-based method?
- Is peptide-level interpretation enough, or is a structure-aware follow-up method also needed?
- What thresholds will define candidate selection after enrichment analysis?
- negative and positive control samples
- replicate strategy for assessing hit reproducibility
- approach to background subtraction and thresholding
- rules for prioritizing enriched peptides
- a staged alternative if the first-pass design proves too broad or too narrow
- whether enriched peptides map to the expected antigen space
- whether controls behave as planned
- whether the number of candidate hits fits the validation budget
- whether replicate samples support acceptable hit reproducibility
- whether selected targets hold up under orthogonal confirmation
Choose a proteome-wide library for PhIP-Seq when the study needs broad antibody discovery across many proteins or organisms, a pathogen-focused library when the agent or antigen family is already defined, and a custom peptide library when the question centers on selected proteins, variants, or dense epitope mapping. The best choice starts with study intent, not library size.
A poor match creates predictable problems. If the library is too broad, library complexity, sequencing demand, and hit triage expand quickly. If it is too narrow, relevant antibody binding outside the panel may never appear. If a team goes custom too early, the design can lock the study into assumptions that have not yet been tested. A practical selection workflow is to define the biological question, match it to antigen coverage and linear epitope needs, and build the validation plan before ordering the assay.
Where Teams Usually Get Stuck
Library selection often gets messy when the team has limited serum or plasma, a mixed cohort, or pressure to combine discovery and follow-up screening in one project. A translational group may want broad discovery of unexpected antibody targets, while an infectious disease team may only need focused profiling of one pathogen family. The hard part is deciding what the phage-displayed peptide library should contain before immunoprecipitation, next-generation sequencing, and reporting criteria are finalized.
The mismatch usually shows up after the experiment starts. Early sequencing metrics may look fine, yet the project still misses the point because the library does not fit the decision question. A broad library can return a long list of low-priority signals that are difficult to sort out at the peptide level. A narrow library can generate clean data while leaving important biological gaps. A custom design can give elegant tiling for selected proteins but still fail if those proteins were the wrong starting choice.
Why Library Selection Goes Wrong
Most selection errors in this setting come from four planning gaps.
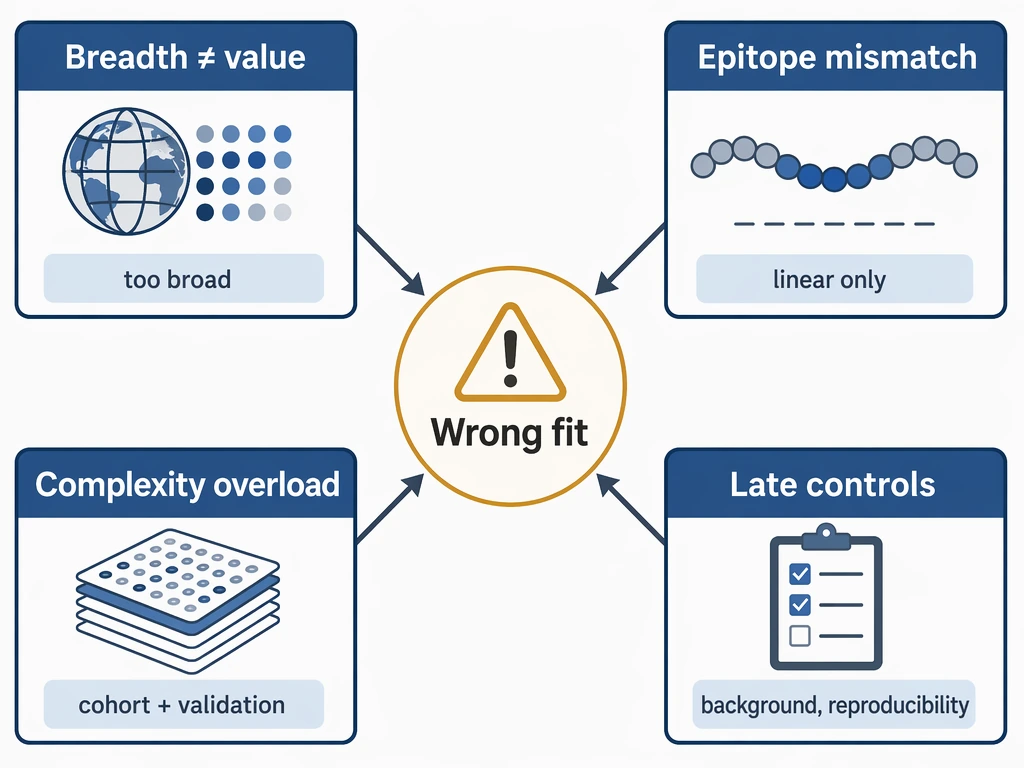
First, teams confuse discovery breadth with study value. Wider antigen coverage does not automatically produce a better result if the project only needs targeted screening of a defined organism or antigen set.
Second, the epitope question is often underspecified. PhIP-Seq is strongest for linear epitope detection and peptide-level interpretation. Expanding library scope will not solve a study that actually needs conformational binding information or full-length protein context.
Third, teams underestimate the link between library complexity, cohort size, and validation workload. A large cohort paired with a broad library can create more candidate hits than the group can realistically review and confirm.
Fourth, control planning is left too late. Without a clear validation plan, background signal handling, and rules for hit reproducibility, even a well-designed screen can produce ambiguous priorities.
If the project is already leaning toward a narrower content set, submit your requirements to MtoZ Biolabs so the library scope, tiling density, and follow-up plan can be checked against the study design before anything is ordered.
Related Services
Main Service
Supporting Service
Validation Service
Alternative Service
Step-by-Step Solution for Choosing the Right PhIP-Seq Library
Step 1: Define the study decision before choosing the library
Write down the exact decision the assay has to support. Is the project trying to discover unexpected antibody targets across a broad antigen landscape? Compare responses to a known pathogen across many samples? Map sequence-level differences among variants or vaccine antigens?
Most projects fall into one of three categories:
If the team cannot place the project in one of these categories, it is too early to order the library.
Step 2: Translate study constraints into library design needs
Next, collect the project inputs that directly affect library fit: sample type, cohort size, organism scope, expected antigen diversity, and whether subgroup comparisons matter.
Then connect those inputs to design choices:
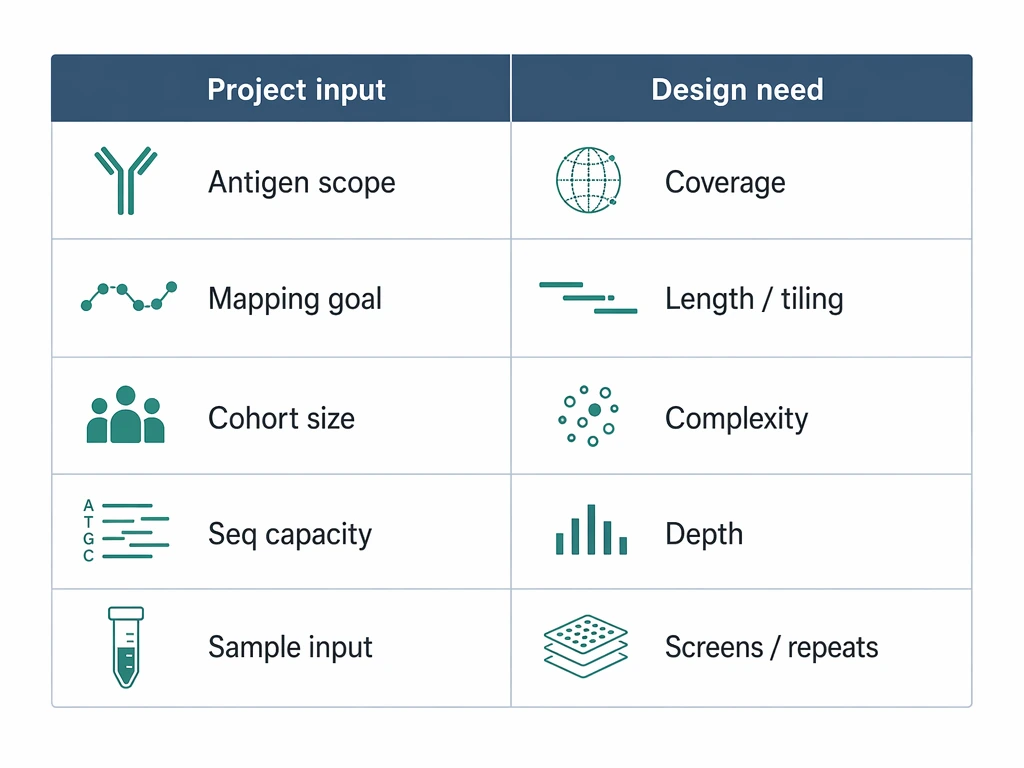
For example, a 20-sample exploratory study can often support a broader first-pass screen. A large cohort tied to one infectious agent usually does better with narrower content and tighter interpretation.
Step 3: Choose among proteome-wide, pathogen-focused, and custom designs
A direct comparison is usually more useful than choosing by habit.
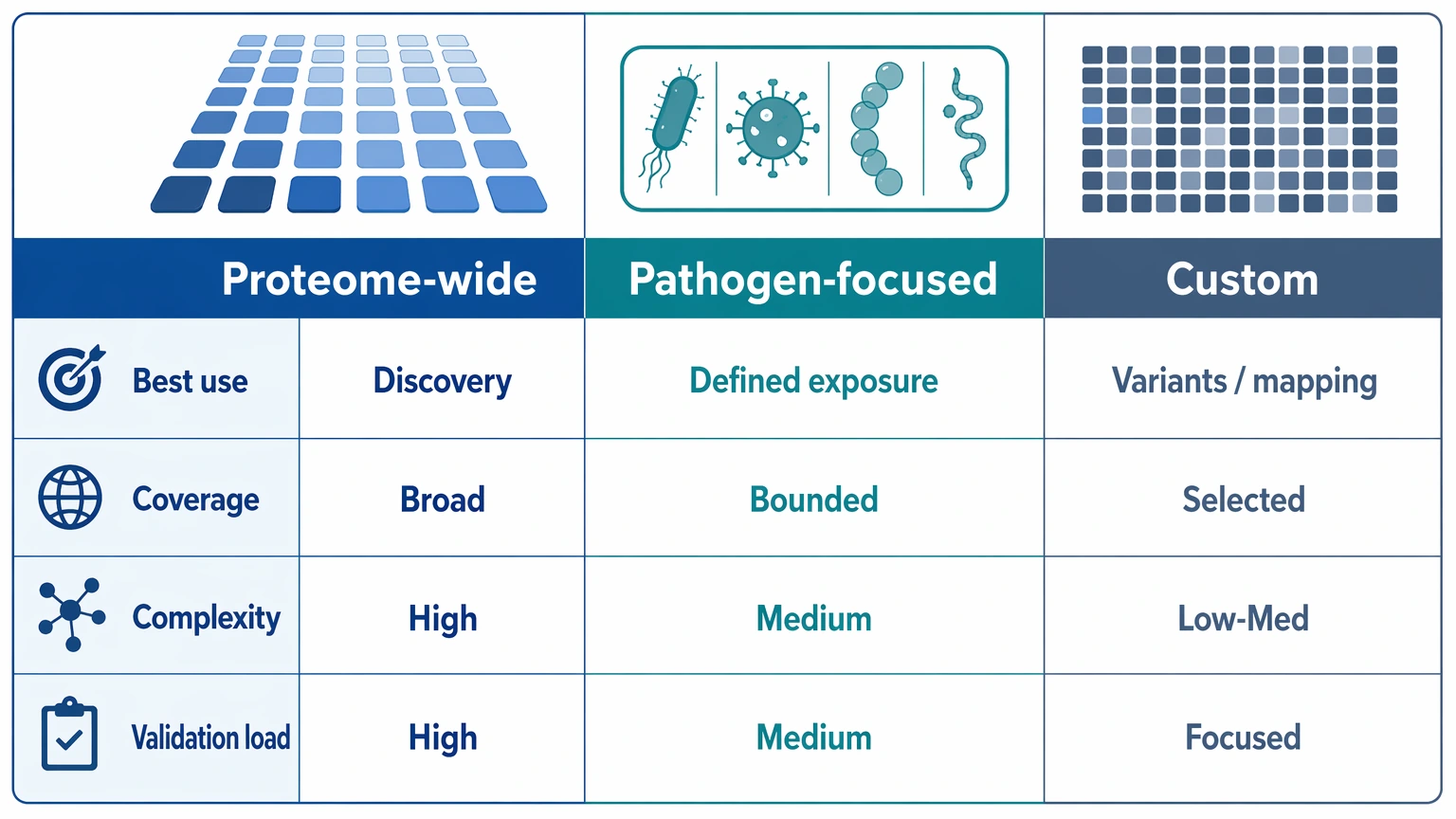
Proteome-wide library
Use this format when the study needs broad discovery across many proteins, possible host-pathogen exposures, or poorly defined antibody targets. It works well when prior assumptions are weak and the team can support more extensive enrichment analysis and follow-up triage. The tradeoffs are higher sequencing burden, more background signal, and a larger validation queue.
Pathogen-focused library
Use this when the question is already bounded to one pathogen, a pathogen family, or a defined infectious exposure panel. A narrower content set often improves interpretability because the candidate list is easier to review and compare across samples. This format fits cohort studies, seroprofiling around known exposure, and projects that already have a shortlist for follow-up testing.
Custom peptide library
Use this when the project needs selected proteins, mutation panels, strain variants, vaccine antigens, or dense tiling for epitope mapping. This option makes sense when the hypothesis is specific enough to justify focused content design. It is usually a weaker first move when the target landscape is still uncertain.
If the team is weighing a pathogen-focused versus custom design for variant coverage or epitope mapping, you can contact us at MtoZ Biolabs to evaluate your project around tiling density, antigen selection, cohort structure, and planned orthogonal confirmation.
Step 4: Match the screening library to the validation path
A good selection decision accounts for what happens after screening, not just what happens during screening. PhIP-Seq detects antibody binding through immunoprecipitation and sequencing of enriched peptides, so positive signals still need orthogonal confirmation before strong biological or translational claims are made.
Before finalizing the library, ask:
This step often changes the recommendation. A proteome-wide library may look attractive at the planning stage, but a pathogen-focused library or custom peptide library may create a cleaner path if only a limited number of hits can be validated.
Step 5: Build an ordering plan that reduces avoidable risk
Before ordering, turn the choice into an operating plan. Document the selected library type, controls, replicate structure, hit-ranking rules, and fallback options.
A practical plan should include:
For projects that combine discovery and follow-up screening, a staged design often works well: screen a smaller subset with a broader library, then move to a narrower library for expanded cohort testing.
What Good Results Should Look Like
A well-matched library should make the dataset easier to read, not just larger. In the early analysis, the hit set should align with the study objective, stay manageable for review, and show acceptable consistency across replicates or related cohort groups. The sequencing output should also support the intended level of peptide-level interpretation.
Useful checks include:
Key Limits to Keep in Mind
PhIP-Seq has clear strengths, but it also has clear boundaries. It is well suited to linear epitope discovery and screening across peptide libraries. It is not a universal replacement for assays that need conformational epitope detection, functional neutralization measurements, or calibrated absolute quantitation.
Sample limits matter early too. If serum or plasma is scarce, repeated screening and broad validation panels may not be realistic. Batch-to-batch and run-to-run differences can also affect background signal, especially when interpreting borderline hits. When the biological question shifts toward full-length protein context or nonpeptide antigen presentation, a different assay format may fit better than forcing the wrong PhIP-Seq library.
Conclusion
The right PhIP-Seq library is the one that matches the project decision: a proteome-wide library for broad discovery, a pathogen-focused library for defined antibody profiling, or a custom peptide library for focused proteins, variants, and dense mapping goals. In discovery programs, pathogen seroprofiling studies, and targeted epitope-mapping workflows, the stronger plan is to align library scope with antigen breadth, expected sequencing burden, and a realistic validation plan before the first screen begins. If your team is preparing a PhIP-Seq study, contact MtoZ Biolabs to discuss the assay workflow, evaluate your project, and plan downstream confirmation for the library type that fits the question.
FAQ
When is a staged two-library strategy better than choosing one library from the start?
A staged design is useful when the project has both discovery and scale-up goals. Teams often start with a broader library in a smaller subset to identify candidate regions, then move to a narrower pathogen-focused or custom design for larger cohort screening.
Do animal studies change the library choice?
Yes. Species differences can affect antigen prioritization, expected exposure history, and background reactivity. In animal studies, library content often needs tighter alignment to the organism of interest and the experimental model rather than relying on a standard human-centered panel.
How should I think about tiling density if variant comparison is the main goal?
When variant comparison is the primary objective, tiling density should be high enough to separate neighboring sequence changes and preserve local context across peptide overlaps. Sparse tiling may detect a reactive region but miss the exact sequence shift that distinguishes one variant from another.
What controls are most useful when the cohort is small or hard to replace?
In small or rare cohorts, controls should be chosen to protect interpretation. Negative controls, replicate samples when possible, and known reference reactivity samples can help distinguish genuine enrichment from assay noise without consuming the entire sample set.
What is the clearest sign that a custom peptide library is justified?
A custom design is usually justified when the study already has a defined antigen set, a variant panel, or a mapping hypothesis that cannot be answered well with a standard broad or pathogen-focused library. The strongest case is when content selection and follow-up testing are already linked in the study plan.
How to order?

