





PhIP-Seq Protocol Planning for Serum and CSF Projects: Controls, Library Scope, and Sample Inputs
- CSF volume is limited, but no material has been reserved for ELISA or cell-based assay follow-up.
- The study requests a whole-human peptidome library plus added viral content without a defined hit triage plan.
- Controls are described only as healthy samples, with no mock IP / bead-only control or repeated batch controls.
- A paired serum-CSF comparison is a major objective, but the matrices are being treated as directly equivalent.
- High-Throughput Peptide Epitope Mapping Service
- Peptide Array-Based Epitope Mapping Service
- Antibody-Antigen Interactions Characterization Service | HDX-MS
- blank or no-sample negative control runs
- mock IP / bead-only control runs
- healthy matrix controls when biological baseline matters
- disease controls or reference sera when group comparison matters
- repeated batch controls across runs
- a documented control map for each batch
- a justified library scope linked to the study question
- a sample allocation sheet that includes orthogonal validation reserve
- a replicate and sequencing depth plan matched to matrix type
- metadata standards for interpreting enriched candidates
A serum or cerebrospinal fluid (CSF) antibody profiling study is ready for PhIP-Seq only when the team settles three decisions before kickoff: which controls will separate true enrichment from background binding, which library scope matches the biological question, and how much sample must be held back for orthogonal validation. If any of those choices is weak, next-generation sequencing may still produce reads while the study remains hard to interpret.
That logic matters even more for CSF than for serum. Serum projects usually allow broader discovery designs and more repeat options. CSF projects often come with tighter volume limits, lower total immunoglobulin signal, and less room to recover from a control or input mistake. A workable phip seq protocol therefore starts with study design discipline, not bench-level settings.
Where Planning Problems Usually Start
Most weak projects are not derailed by failed sequencing. They start when a team tries to make one study answer too many questions at once. Archived serum, prospectively collected serum, low-volume CSF, and paired serum-CSF samples may all be available, but they should not be folded into one design without separate assumptions for each matrix.
Common warning signs include:
When those choices stay vague, the project can consume scarce samples and still end with ambiguous peptide-level hits, heavy nonspecific enrichment, or filtering rules that are difficult to defend.
Why PhIP-Seq Studies Become Hard to Interpret
Four planning failures account for most interpretation problems in serum and CSF projects.
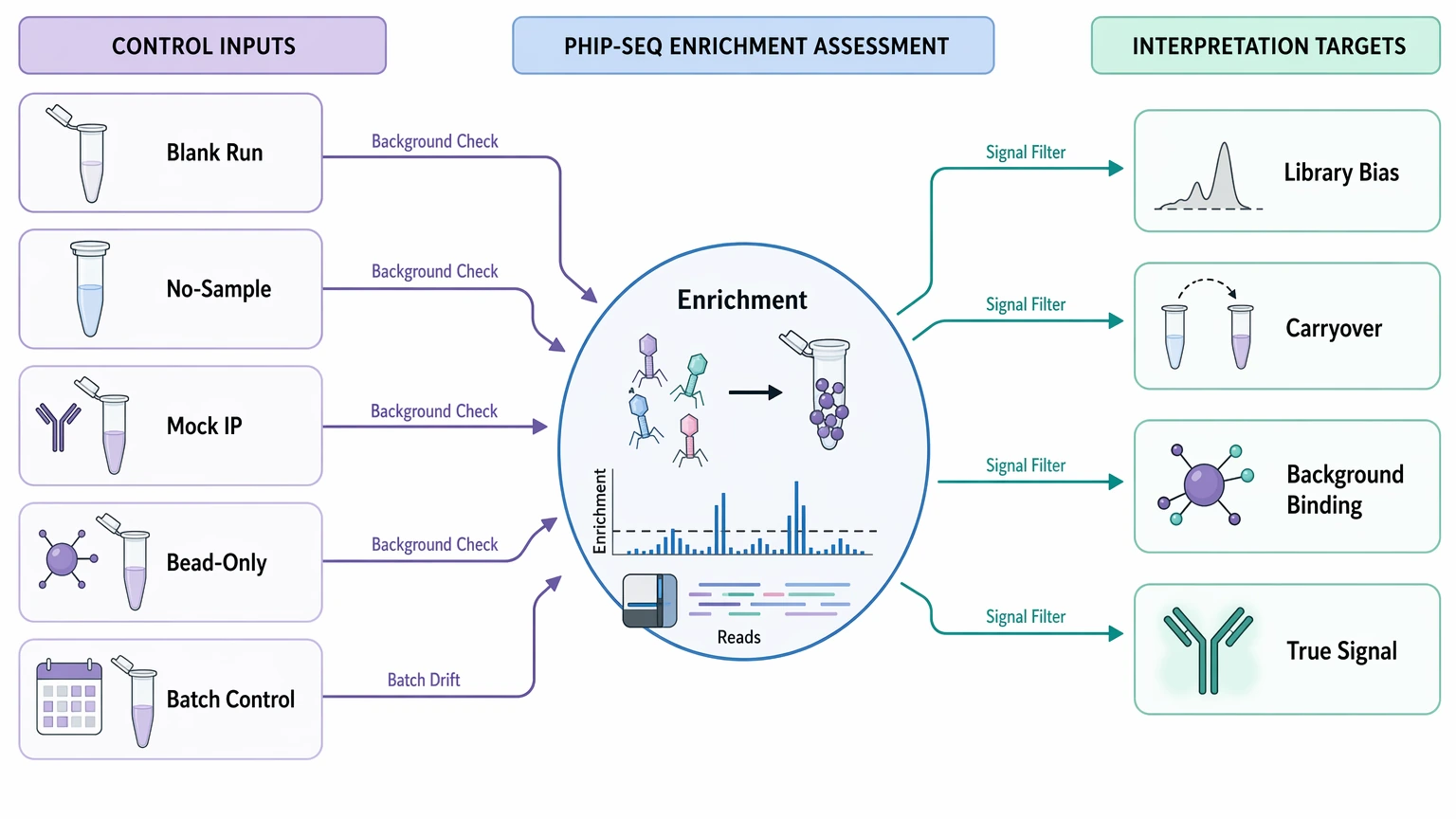
1. Control design is too thin
A negative control is not a formality in PhIP-Seq. Blank runs, no-sample negative control runs, mock IP / bead-only control reactions, and repeated batch controls help separate antibody-driven enrichment from library bias, carryover, and background binding. Without those references, enriched peptides may look convincing on paper but remain difficult to trust.
2. Library scope is chosen for breadth alone
A broader phage-displayed peptide library expands discovery space, but it also increases the candidate list, raises the multiple-testing burden, and creates more antigen prioritization work. That cost matters when the disease hypothesis is already narrow or when little sample remains for confirmation.
3. Sample input is planned without a validation reserve
Teams often allocate enough material for the first immunoprecipitation and sequencing run, then realize the best hits still need orthogonal validation. In CSF, that mistake is expensive because the remaining specimen may be too limited for repeat work, ELISA, or a cell-based assay.
4. Serum and CSF are treated as interchangeable
Both matrices can support antibody profiling, but they differ in signal strength, background composition, and practical repeatability. A paired serum-CSF comparison can be informative, but only if the study acknowledges matrix asymmetry instead of expecting matched enrichment behavior.
Related Services
Main Service
Supporting Service
Validation Service
Alternative Service
A Project-Planning Guide for PhIP-Seq Readiness
Step 1: Define the study decision before choosing assay breadth
Start with the decision the study must support. Is the goal open discovery, comparison across phenotype groups, paired serum-CSF comparison, or follow-up of a narrower autoimmune hypothesis? That choice sets the right level of library scope, control density, replicate planning, and follow-up burden.
A broad discovery objective may justify a larger library and more complex hit triage. A targeted hypothesis study often benefits from a narrower design with clearer downstream validation. If the team cannot state what result would justify the next project phase, the protocol is not ready.
Step 2: Build controls around background binding and batch effect
Controls should support enrichment analysis, not merely document that the assay ran. For most serum and CSF studies, planning should include:
Serum projects often leave room for a broader control set. CSF projects usually force a leaner design, which makes each control more informative. If both matrices are included, randomize serum and CSF specimens across batches rather than processing them in separate blocks. That reduces the risk of confusing batch effect with disease-related enrichment.
Step 3: Match library scope to hypothesis strength and follow-up capacity
Library scope should reflect what the team can realistically interpret and validate. A whole-human peptidome library may fit an open discovery cohort with strong metadata and a credible post hoc filtering plan. A focused autoimmune panel, viral-augmented library, or custom antigen subset may be easier to defend when the hypothesis is narrower or the sample pool is small.
Broader is not automatically better. A larger library often increases peptide-level hits, but a longer candidate list can slow validation and weaken decision-making if only a few candidates can be followed up. When residual CSF volume is modest, a narrower library can produce the stronger overall study because the confirmation burden stays manageable.

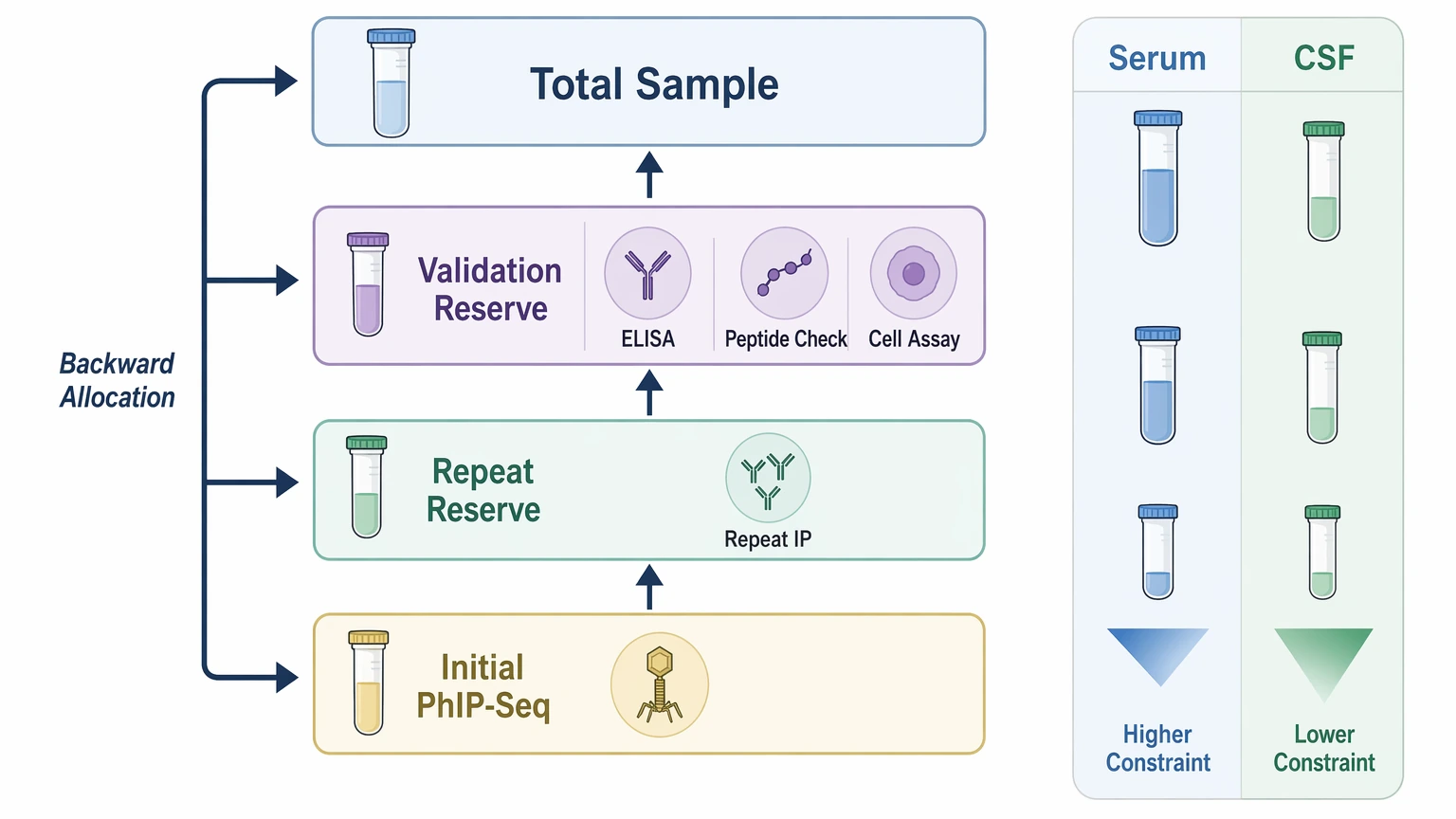
Step 4: Budget sample input backward from confirmation needs
The central sample-planning question is not the smallest workable input. It is how much material must remain after the primary assay for orthogonal validation and repeat decisions.
A practical sequence is:
1. reserve material for ELISA, peptide-based confirmation, or cell-based assay follow-up 2. reserve contingency volume for repeat immunoprecipitation if background binding is higher than expected 3. assign the remaining material to the initial PhIP-Seq plan
This constraint is usually tighter in CSF than in serum because lower antibody abundance and lower total volume limit repeat testing. If your team is balancing matrix type, planned controls, and confirmation reserve, submit your requirements to MtoZ Biolabs to evaluate the project before scarce specimens are committed.
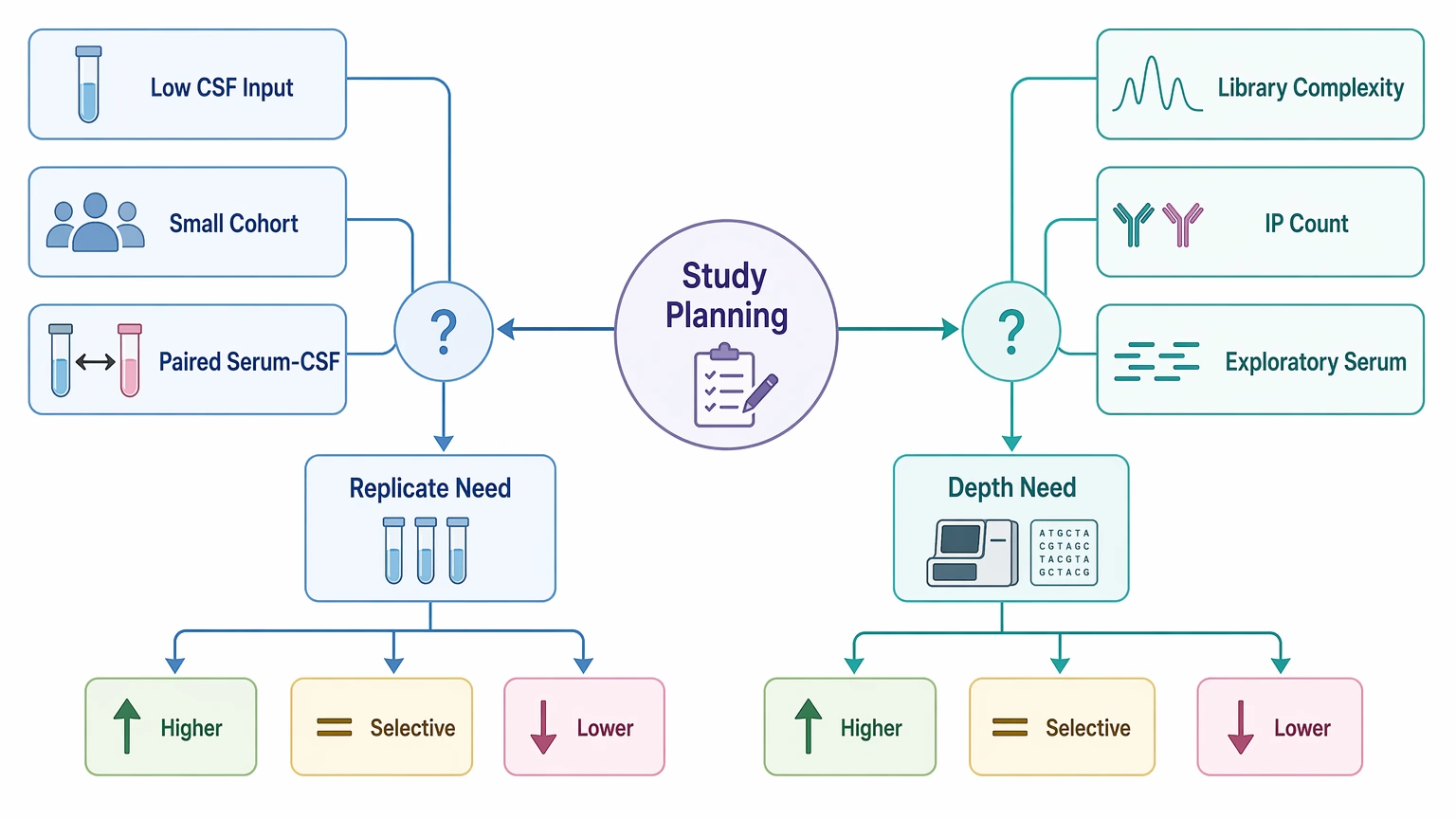
Step 5: Set replicate and sequencing depth expectations before launch
Replicate strategy should follow decision risk. Technical replicates are more justifiable when CSF input is low, the cohort is small, or a paired serum-CSF comparison is central to the study. Exploratory serum work may not require duplicates for every sample, but the study should identify where a replicate adds real interpretive value.
The same principle applies to sequencing depth. Greater depth may improve representation across a complex phage-displayed peptide library, yet depth planning should follow library complexity and the number of immunoprecipitation reactions rather than a generic more-is-better assumption.
Step 6: Define hit triage and metadata needs before data exist
Interpretation readiness should be planned before wet-lab start. Decide whether filtering will emphasize peptide-level hits, gene-level aggregation, known disease antigens, or matrix-specific comparison patterns. Also define which metadata must accompany each sample. Diagnosis group, collection timing, treatment context, freeze-thaw history, and storage conditions can all shape how enriched peptides should be read.
This is also the point to define what qualifies as validation-worthy. PhIP-Seq is strongest for linear epitope reactivity and does not capture all conformational recognition. If a project depends on native structure or membrane context, the initial screen may still be useful, but the follow-up method will need to carry more of the biological interpretation. At that stage, contact MtoZ Biolabs to discuss assay workflow, control architecture, and the planned validation path.
Readiness Checks Before Kickoff
Before launch, confirm that the study has:
Also state the assay limits clearly. Pre-analytic handling still matters, including freeze-thaw history and storage consistency. During analysis, enriched peptides should not be read as calibrated antibody concentration. PhIP-Seq reports relative enrichment patterns, not ELISA-like absolute quantitation. Those limits do not block useful discovery, but they do shape how confidently hits can move into validation.
Conclusion
A strong PhIP-Seq plan for serum or cerebrospinal fluid (CSF) rests on three linked decisions: controls that support enrichment interpretation, library scope that fits the study question, and sample allocation that preserves orthogonal validation. That framework is especially useful for exploratory serum cohorts, low-volume CSF studies, and paired serum-CSF comparison projects where matrix asymmetry and hit triage burden determine whether the study should proceed now, be narrowed, or be staged. If your group is at that point, submit your requirements or contact us with sample type, available volume, cohort structure, and validation goals so the project can be scoped realistically before kickoff.
FAQ
Should healthy controls and disease controls both be included in the same PhIP-Seq study?
Not always. Healthy controls are useful for establishing baseline background patterns, while disease controls matter more when the study asks whether enrichment differs across clinical groups. If the design cannot support both, prioritize the control type that answers the main decision question.
When does a paired serum-CSF comparison add value?
It adds value when compartment-specific antibody profiling is biologically important, such as comparing systemic and intrathecal reactivity. It becomes harder to interpret when sample volume is uneven, metadata are incomplete, or the analysis plan assumes the two matrices should show the same enrichment profile.
Can a focused library reduce false positives?
Not by itself. A focused library can reduce hit triage burden and make downstream antigen prioritization more practical, but background binding and nonspecific enrichment still require careful controls and filtering.
When is gene-level aggregation more useful than peptide-level review?
Gene-level aggregation is helpful when several related peptides converge on the same antigen and the study goal is candidate prioritization. Peptide-level review remains important when a specific linear epitope pattern may guide validation design.
What information should a team send before finalizing project launch?
A useful planning package includes sample type, available volume per specimen, cohort layout, freeze-thaw history, intended controls, preferred library scope, replicate priorities, and the expected orthogonal validation route. That makes it easier to judge whether the current study design is feasible or needs revision.
How to order?

