





Antibody Protein Sequencing vs DNA-Based Clone Sequencing: Which Route Answers Your Project Question?
Use antibody protein sequencing when the main question is, “What sequence is actually present in the purified antibody product I have?” Use DNA-based clone sequencing when trusted source cells or an expression construct are still available and the immediate goal is to recover the encoded VH and VL sequence for recombinant re-expression. When both a product sample and a putative clone record exist but may not agree, a combined strategy often answers the project question more directly than either route on its own.
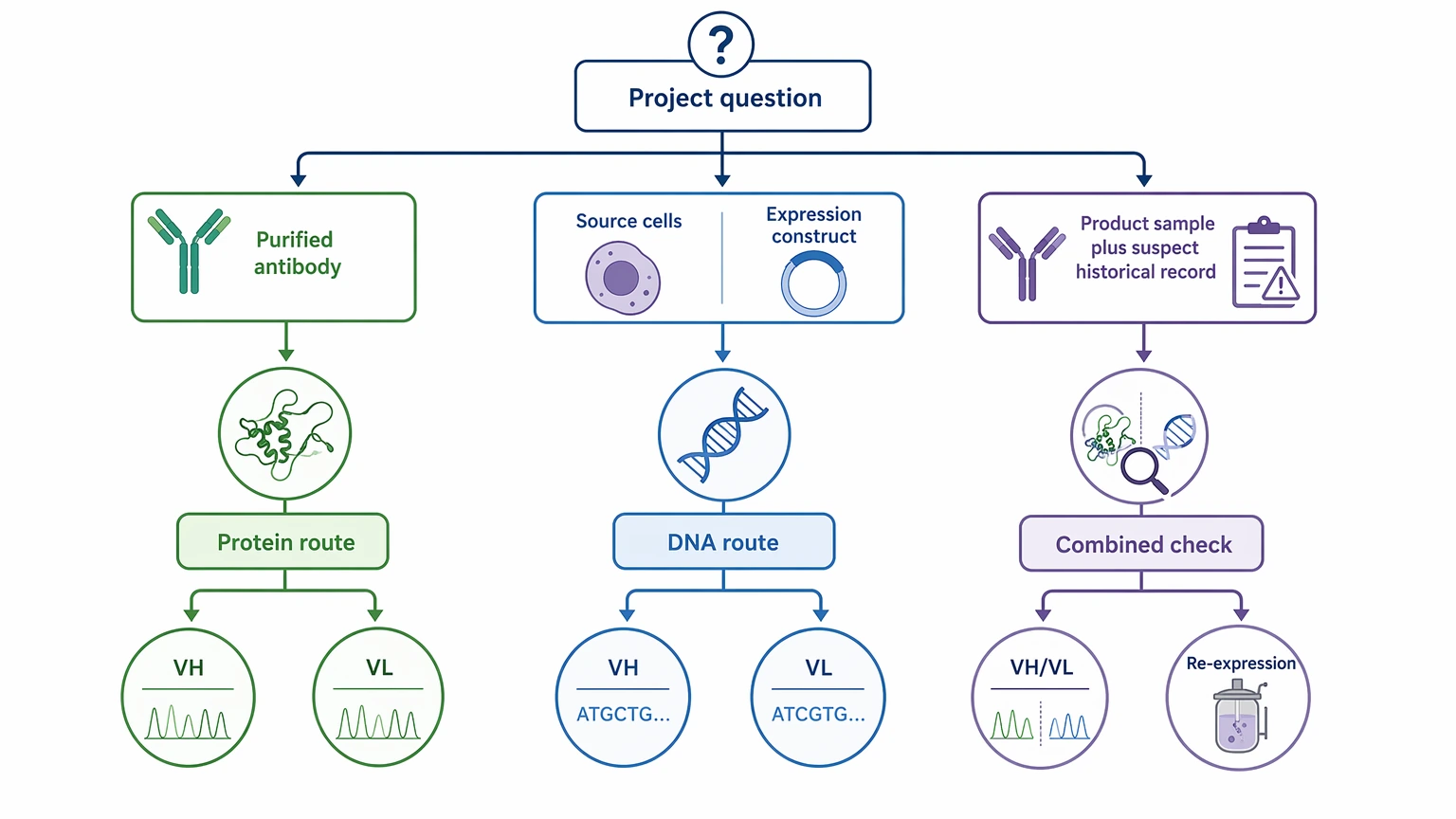
The distinction matters because these methods do not produce the same kind of evidence. Antibody protein sequencing starts from the expressed monoclonal antibody and generates product-level sequence evidence. DNA-based clone sequencing starts from hybridoma, other source cells, or an expression construct and generates source-genetic sequence evidence. That difference affects how you read CDR / complementarity-determining region assignment, full variable region recovery, heavy/light chain pairing, and the validation still needed before downstream use.
What question are you really trying to answer?
Many teams say they need “the antibody sequence,” but that phrase often covers two different goals.
One goal is sequence recovery from the actual product. This usually comes up when a legacy vial, reference lot, or purified antibody is the only dependable material, or when the available DNA records look incomplete or questionable. In that situation, the project needs evidence from the molecule that was expressed, purified, and stored.
The other goal is sequence recovery from the source clone. This is common when a viable hybridoma, B-cell-derived material, or documented construct still exists and the next milestone is recombinant reconstruction. In that case, the project usually needs the encoded heavy chain and light chain sequence as efficiently as possible.
There is also a middle case: the team has both a purified product and a historical sequence record, but it does not know whether they still match. That is not a generic sequencing request. It is a sequence confirmation problem, and it often benefits from comparing product-level and source-genetic evidence instead of choosing only one.
Where this choice shows up in real antibody programs
This decision usually shows up after an antibody asset already exists but its provenance is uneven.
A development group may inherit a purified monoclonal antibody with no trusted plasmid archive. A platform team may still have hybridoma material and want the cleanest route to a usable VH and VL sequence. A CMC or analytical team may hold both a purified lot and an archived record yet still need to verify whether the expressed product matches the documented clone.
In each case, the route should follow the project decision, not the platform label. If the real issue is product identity, clone-derived sequencing may recover an encoded sequence while still leaving uncertainty around product-clone mismatch, sequence drift, truncation, or clipping. If the real issue is quick clone reconstruction from intact biological source material, de novo antibody sequencing may add useful product-level detail, but it may not be the first requirement for the next step.
Four comparison dimensions that matter most
A practical comparison gets clearer when you judge both routes across four project-level dimensions.
1. Sequence truth source
This is the central distinction.
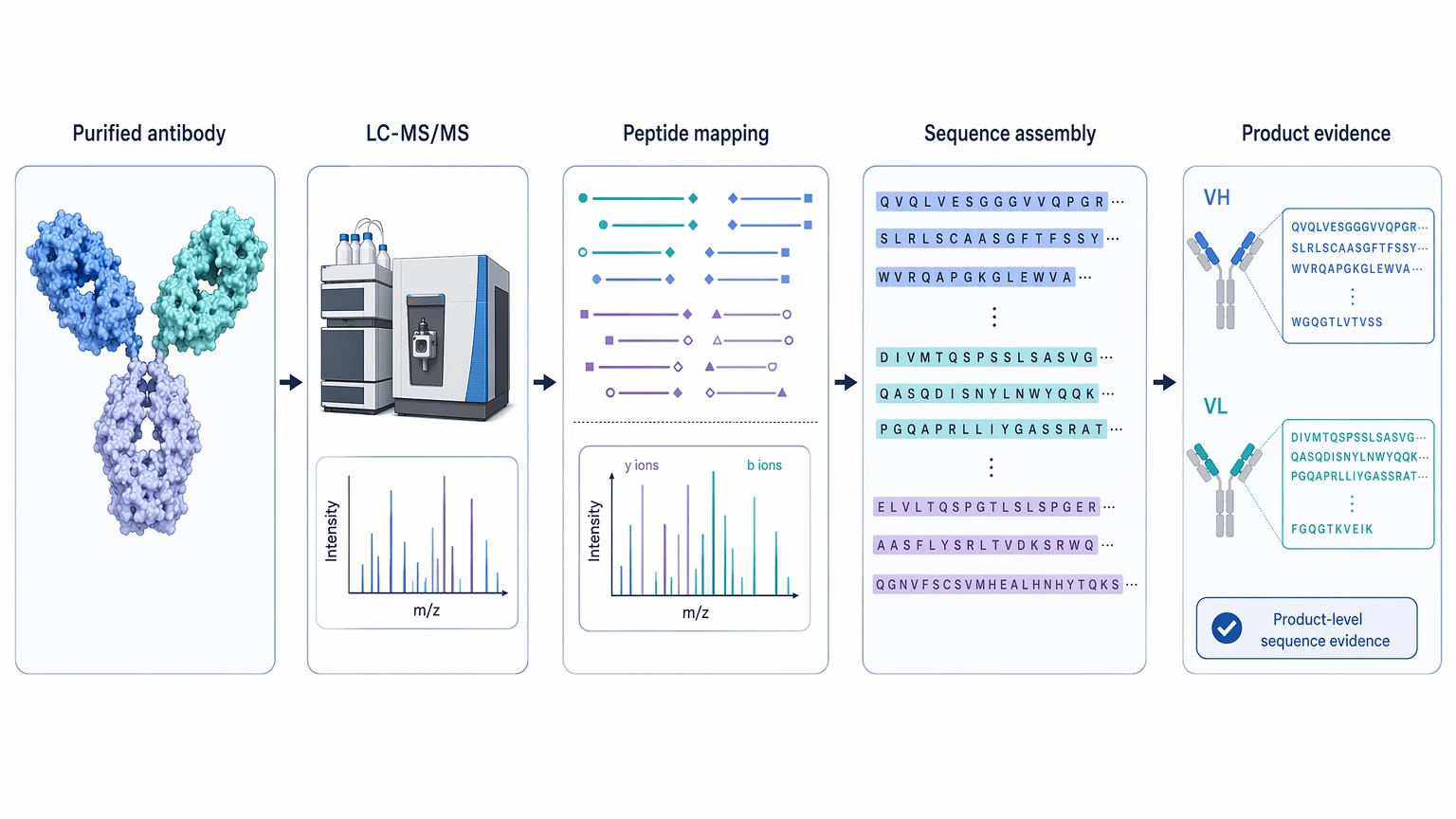
Antibody protein sequencing reads the expressed antibody molecule through LC-MS/MS, peptide mapping, and sequence assembly. That makes it a strong fit for questions about the antibody lot or purified product in hand.
DNA-based clone sequencing reads nucleic acids from hybridoma, source cells, or constructs, typically using RT-PCR, RACE, Sanger sequencing, or NGS. It fits questions about what the source is encoded to express.
If the project needs to know what is present in a stored antibody vial, product-level sequence evidence is usually the more relevant layer. If the project needs to rebuild the clone for expression and the source remains intact, source-genetic sequence evidence is often the more direct starting point.
2. Starting material and sample constraints
Starting material often narrows the choice before platform preference does.
| Starting material | Usually favors | Main reason |
|---|---|---|
| Purified antibody only | Antibody protein sequencing | No source nucleic acid is available for clone-derived sequencing |
| Formulated monoclonal antibody | Antibody protein sequencing | The product is available, though formulation components may complicate preparation |
| Viable hybridoma | DNA-based clone sequencing | Direct access to source-genetic sequence evidence |
| Source cells with usable RNA | DNA-based clone sequencing | Supports variable-region recovery from expressed transcripts |
| Expression construct | DNA-based clone sequencing | Efficient route to encoded sequence confirmation |
| Purified product plus suspect sequence record | Combined workflow | Tests agreement between expressed product and documented clone |
Protein-derived work is shaped by antibody amount, purity, and formulation background. Clone-derived work is shaped by source identity, nucleic acid quality, and whether the sampled cells or construct still represent the antibody asset under review.
3. Deliverable fit for variable-region recovery and pairing
Not every project needs the same deliverable. Some teams need CDR / complementarity-determining region assignment only. Others need full VH and VL variable region recovery. Others need chain pairing confidence strong enough to support recombinant re-expression planning.
Antibody protein sequencing can recover highly relevant sequence information when the purified product is the only trusted source. It reflects the expressed heavy chain and light chain, which matters when the project depends on the molecule actually in hand. Still, interpretability depends on peptide coverage across framework region and CDR segments, residue ambiguity at isobaric positions, and how well the data support heavy/light chain pairing.
DNA-based clone sequencing often offers a cleaner route to clone-derived heavy chain and light chain recovery when the biological source is intact and correctly linked to the antibody. That is why it is commonly chosen when the next practical need is recombinant reconstruction rather than product verification.
If your team is sorting through those tradeoffs, MtoZ Biolabs can evaluate your project around available sample type, expected sequence recovery scope, and the likely need for orthogonal validation before sequence acceptance.
4. Validation burden after sequence recovery
A recovered sequence is not automatically the final answer. The remaining uncertainty depends on the route.
For antibody protein sequencing, follow-up review often centers on sequence assembly support, residue ambiguity, completeness across key CDR segments, and pairing confidence. For DNA-based clone sequencing, the next question is often whether the recovered source sequence still represents the purified product being discussed, especially when records are old or sample provenance is weak.
That is why some projects should not be framed as protein versus DNA in absolute terms. A better framing is: which evidence layer answers the decision now, and which one may still be needed later?
Side-by-side view of the two routes
| Dimension | Antibody protein sequencing | DNA-based clone sequencing |
|---|---|---|
| Evidence source | Expressed antibody molecule | Source genetic template |
| Typical workflow | LC-MS/MS, peptide mapping, sequence assembly | RT-PCR, RACE, Sanger sequencing, NGS |
| Best-fit question | What is present in the antibody product? | What sequence is encoded in the source clone? |
| Product mismatch detection | Stronger for checking the actual lot in hand | Limited if the product differs from archived DNA |
| Pairing logic | Derived from protein evidence and assembly; may need extra confirmation | Often more straightforward when paired heavy and light chain information is recovered from the same source |
| Re-expression planning | Useful, but usually followed by orthogonal validation | Often the more direct route when clone reconstruction is the next step |
Route selection by project scenario
Choose antibody protein sequencing when the product is the reference point
This route is usually the better fit when the project starts with a purified antibody, a formulated reference material, or a legacy lot without trusted clone records. It is also the more informative choice when the team needs sequence confirmation of the expressed product rather than an inferred sequence from source material.
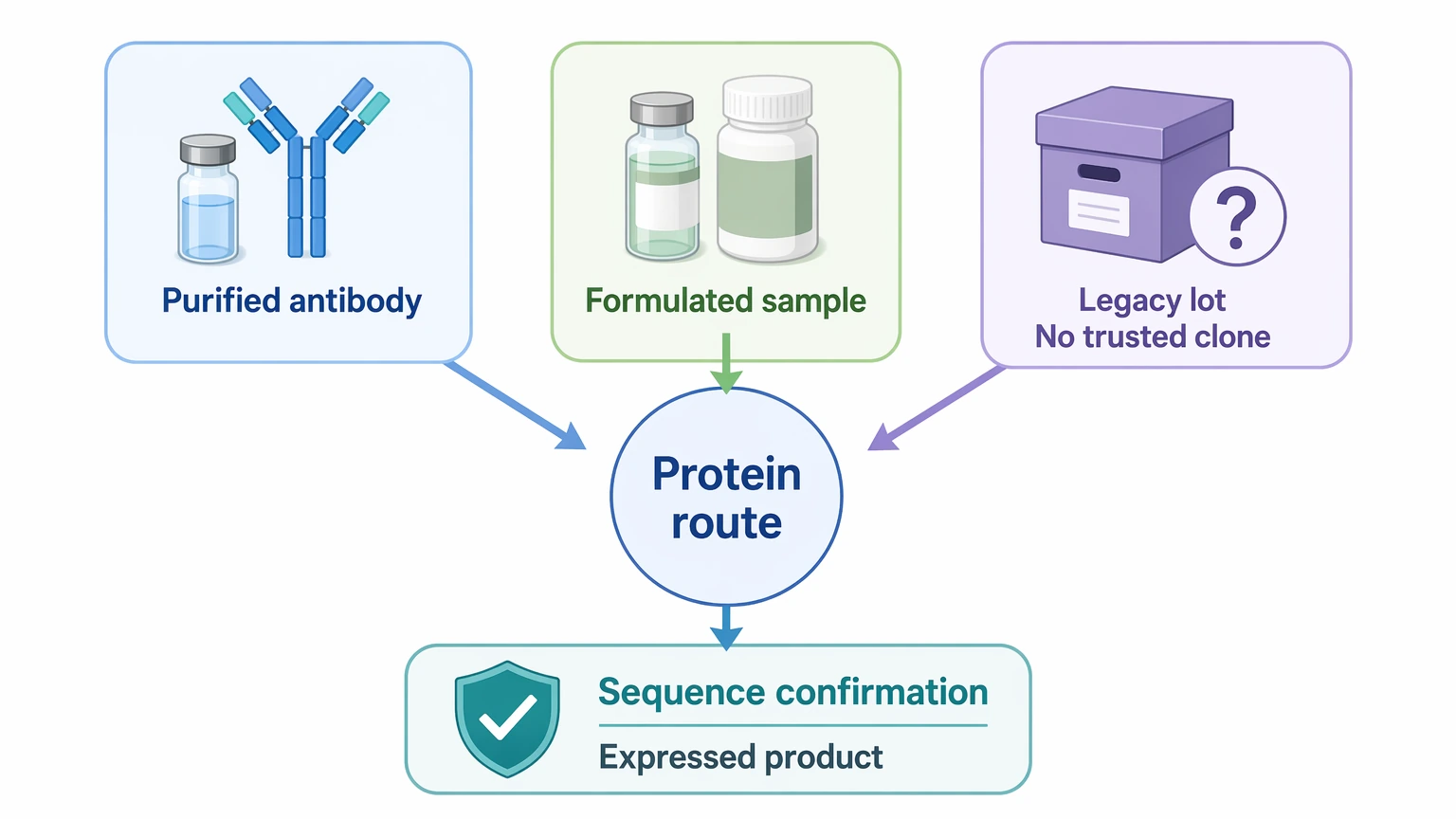
This route is especially relevant for archived assets, transferred materials, or lots with uncertain documentation. Its main boundary is analytical interpretability: the workup must support enough peptide evidence for the variable region, and some projects still need orthogonal follow-up before moving into expression work.
Choose DNA-based clone sequencing when the source remains accessible and trusted
This route is often favored when a hybridoma, source cells, or an expression construct still exists and the project needs encoded VH and VL information for recombinant re-expression. In that setting, clone-derived sequencing usually lines up better with the immediate technical objective.
Its main boundary is not the sequencing chemistry itself but source trustworthiness. If the biological source is mislabeled, degraded, or no longer linked clearly to the purified antibody asset, the output may answer a different question than the one the team actually needs answered.
Choose a combined workflow when recovery and confirmation both matter
A staged approach often makes sense when the team has both a physical product and a historical clone record, or when either one may be incomplete. One practical structure is to recover the clone-derived sequence first, then compare it against product-level sequence evidence from antibody protein sequencing.
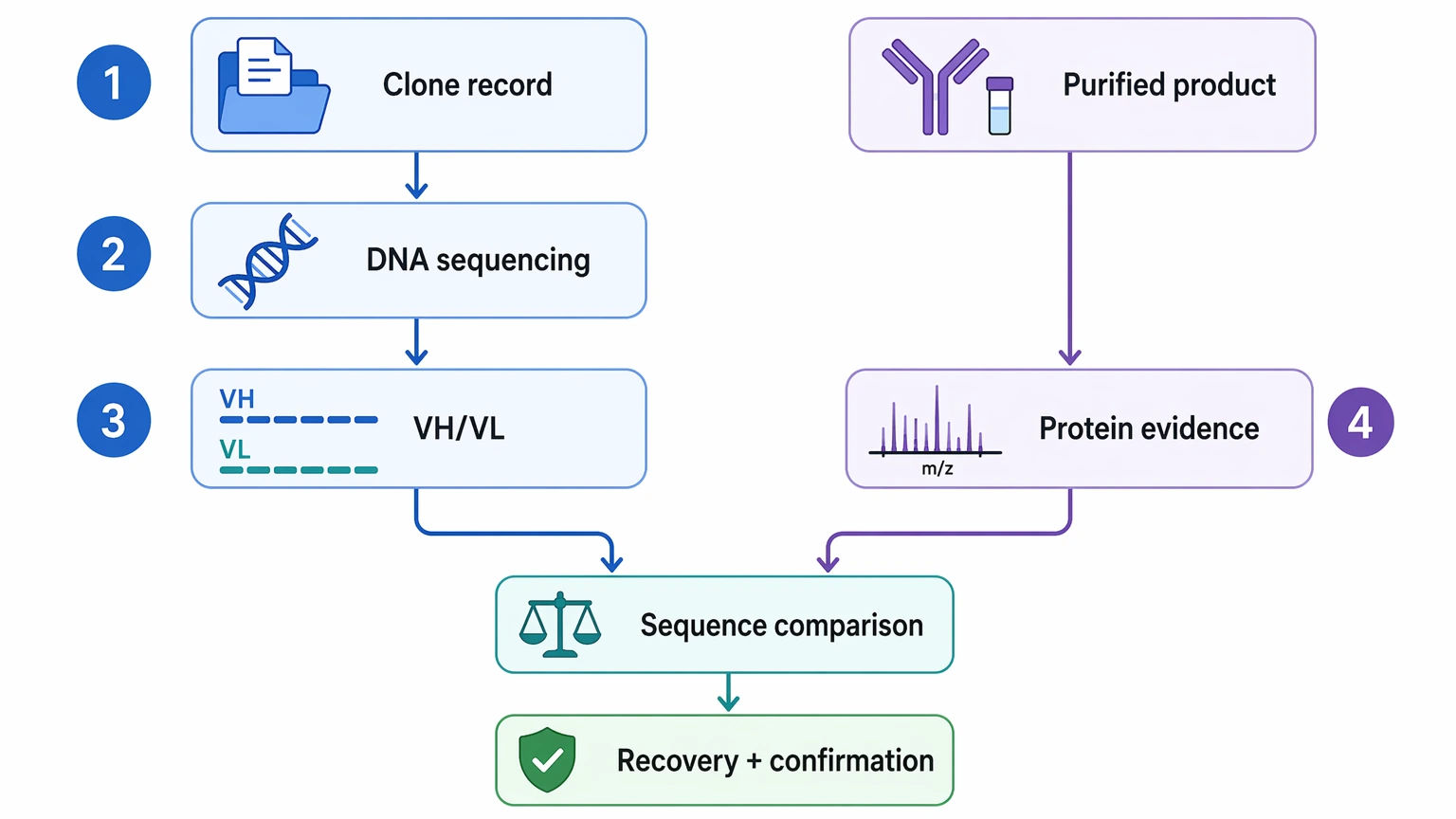
That combined logic is often appropriate for comparability review, legacy asset recovery, or situations where downstream engineering depends on both sequence reconstruction and product identity. If that is your decision point, submit your requirements to MtoZ Biolabs with the sample type, source availability, existing records, and intended deliverable so the route can be matched to the actual use case rather than a default platform choice.
When one route is not enough
Some projects do not run into trouble because sequencing was unavailable. They run into trouble because the selected evidence type did not match the project question.
If the only requirement is encoded clone recovery from intact source material, DNA-based clone sequencing may be sufficient. If the project must verify the actual expressed molecule in a purified vial, antibody protein sequencing becomes central. If the next step is recombinant re-expression but provenance is uncertain, using source-genetic sequence evidence and product-level sequence evidence together can reduce avoidable rework.
The strongest route is the one that answers the next decision with the fewest unsupported assumptions. In practice, that means matching the method to the truth source, the sample in hand, the level of variable-region recovery needed, and the validation burden your team can accept. For legacy products, hybridoma-linked assets, and confirmation-sensitive re-expression programs, a focused feasibility discussion is often more useful than a generic request for “antibody sequencing.” Gather the sample type, quantity, formulation status, source availability, and downstream goal, then contact us to discuss the project and define the most defensible sequencing path.
FAQ
Can DNA-based clone sequencing recover constant-region information that protein sequencing does not?
It can recover the constant-region sequence encoded by the source material if the assay design captures it. That still does not prove the purified lot in hand matches the same constant-region sequence or processing state.
What if my purified antibody contains formulation excipients?
Formulation components do not automatically prevent antibody protein sequencing, but they may affect preparation and data interpretation. A feasibility review should check buffer composition, concentration, and whether cleanup steps are realistic for the material available.
Is NGS always better than RT-PCR or RACE for clone-derived sequencing?
Not always. NGS can broaden recovery options, but the better choice depends on source type, expected diversity, template quality, and whether the goal is targeted sequence confirmation or broader sequence discovery.
Does antibody protein sequencing resolve every amino acid unambiguously?
No. Protein-derived sequence assembly can leave ambiguity at some residues, particularly isobaric positions. Projects that depend on exact expression-ready sequence acceptance often plan orthogonal validation after the initial readout.
If I only need to compare a purified lot against a known candidate sequence, do I need full de novo antibody sequencing?
Not necessarily. Some comparison projects are structured around targeted sequence confirmation rather than full de novo antibody sequencing. The right scope depends on how much of the variable region must be verified and where the uncertainty sits.
What should I prepare before requesting a route assessment?
The most useful inputs are sample type, approximate quantity, purification or formulation status, whether hybridoma or other source cells still exist, any expression construct records, and the downstream purpose such as sequence confirmation, archival recovery, or recombinant re-expression.
How to order?

