





What Is PhIP-Seq? Principles, Applications, Strengths, and Study Design Considerations
- Peptide Array-Based Epitope Mapping Service
- Protein Array Analysis Service
- Antibody-Antigen Interactions Characterization Service | HDX-MS
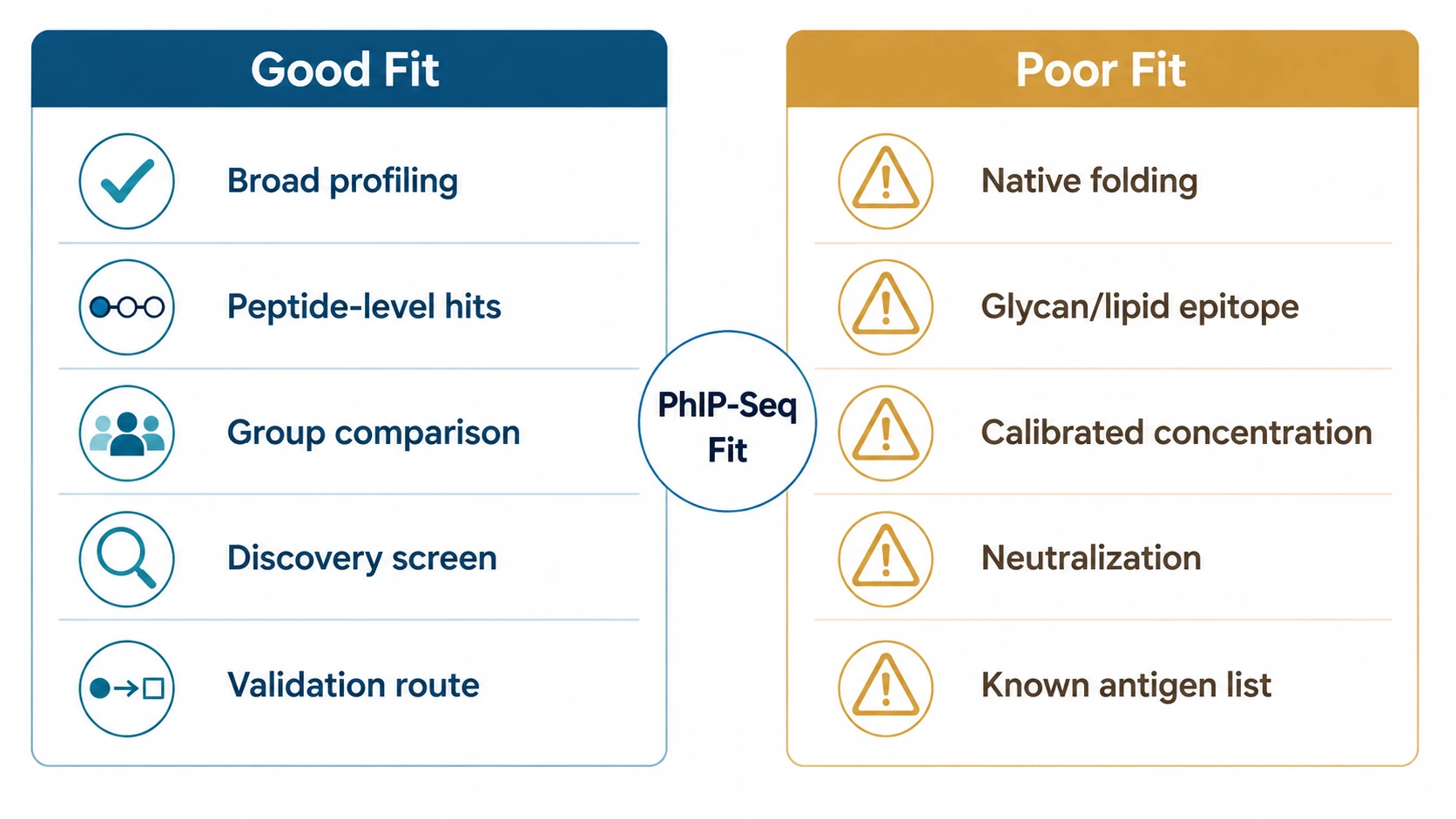
PhIP-Seq is useful when a study needs broad peptide-level antibody profiling, group-wise enrichment comparison, and a clear route into validation. It is a poor fit when the main question depends on native protein folding, glycan or lipid epitopes, calibrated antibody concentration, neutralization activity, or a short list of known antigens that can be tested directly.
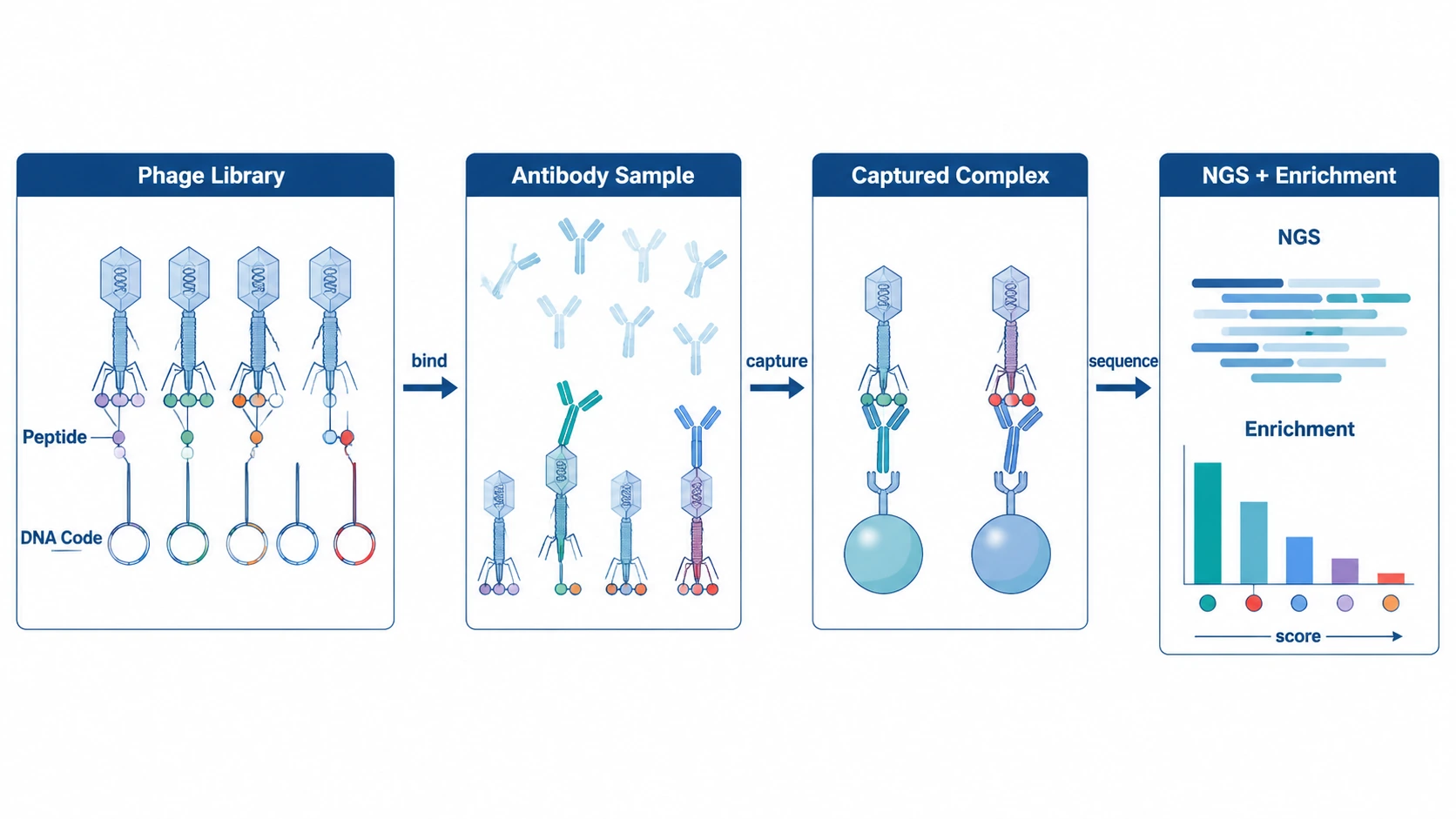
PhIP-Seq, or Phage ImmunoPrecipitation Sequencing, combines a phage-displayed peptide library with antibody capture and next-generation sequencing. The assay reports which displayed peptides are enriched after antibody binding and immunoprecipitation. For discovery-stage serological profiling, that makes it possible to screen large antigen spaces before narrowing candidates for ELISA validation, peptide array validation, recombinant protein assay development, or functional testing.
Authoritative Definition and Why PhIP-Seq Matters
PhIP-Seq is a sequencing-based antibody-binding assay. Bacteriophages display designed peptide sequences on their surface, and the DNA inside each phage identifies the displayed peptide. When serum, plasma, CSF, or another antibody-containing sample is incubated with the library, antibodies can bind compatible peptides. The antibody-phage complexes are captured, sequenced, and analyzed for peptide enrichment.
The method addresses a practical discovery problem: many antigen spaces are too large to test one target at a time. A project may need to examine a viral peptidome, pathogen proteome, human autoantigen set, tumor-associated antigen panel, allergen set, or custom antigen library. PhIP-Seq turns that search into a pooled library experiment with an NGS readout.
PhIP-Seq is not antibody receptor sequencing. BCR sequencing profiles antibody gene repertoires from B cells. PhIP-Seq profiles antibody binding to displayed peptides in antibody-containing samples. It also differs from ELISA, western blotting, peptide arrays, and protein arrays because interpretation depends on clone enrichment, read mapping, library coverage, and statistical comparison rather than direct signal from individual immobilized antigens.
Technical Principle and Workflow
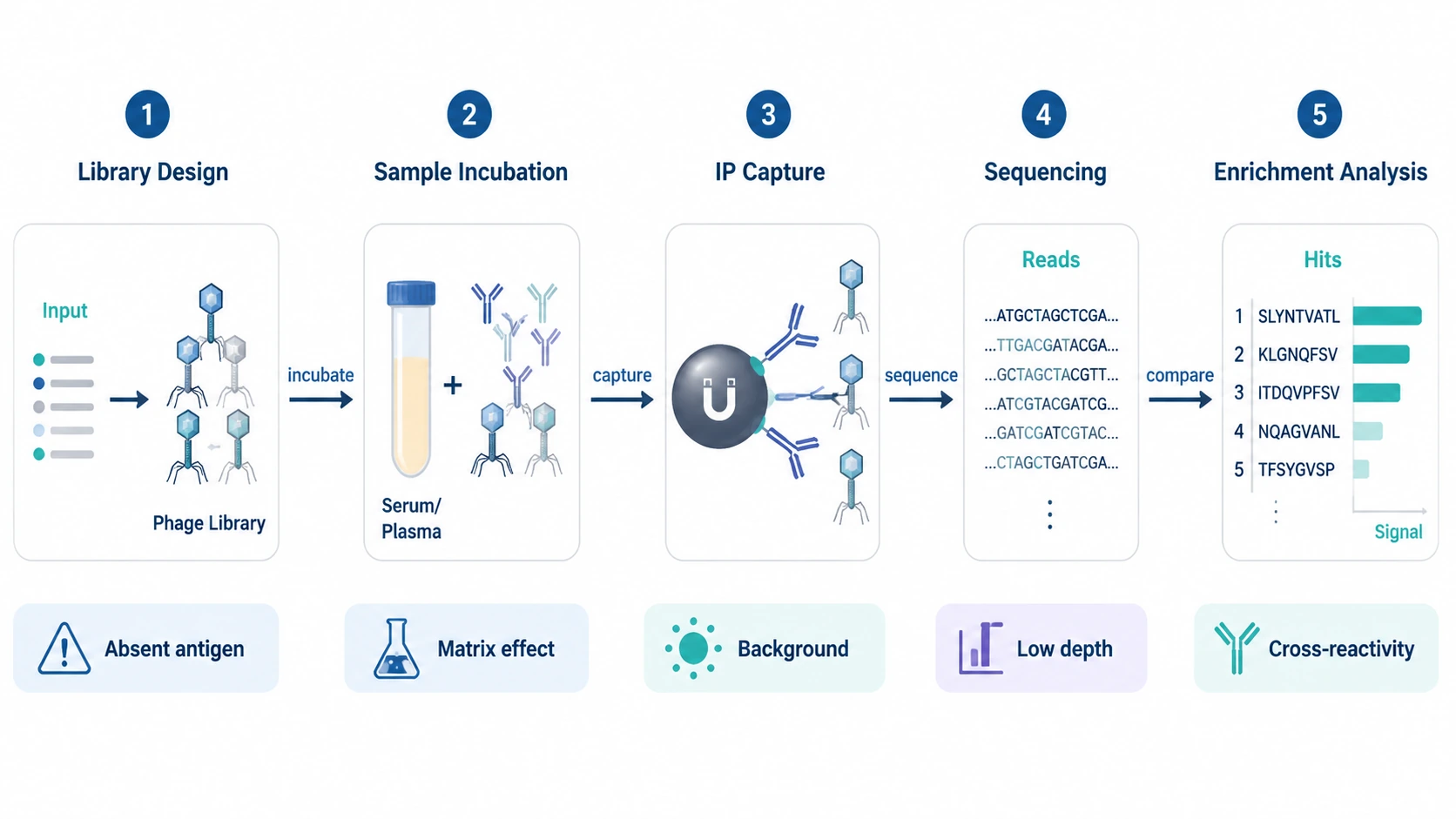
1. Peptide Library Design Defines the Search Space
The input is a peptide library encoded in bacteriophage display format. Each clone carries a DNA sequence corresponding to a displayed peptide. Library design may use tiled peptides across a proteome, overlapping peptides across selected antigens, a viral peptidome, a pathogen-focused antigen library, an autoantigen panel, or a custom antigen set.
This design becomes the reference map connecting clone sequence to peptide identity, antigen source, protein position, and annotation. Check clone representation, library complexity, peptide length, overlap design, library coverage, and whether the library actually contains the antigen regions relevant to the study. If an antigen is absent from the library, analysis will not recover it later.
2. Antibody-Containing Samples Are Incubated with the Library
The sample is usually serum or plasma. CSF may be considered in neurological or neuroimmune studies when antibody abundance and available volume are compatible with the assay. Depending on the question and capture strategy, researchers may focus on IgG, IgA, IgM, or broader immunoglobulin capture.
During incubation, antibodies bind displayed peptides that match their recognition patterns. The mixture contains both bound and unbound phage clones. Sample input, antibody abundance, incubation conditions, nonspecific background, and sample-matrix interference all affect the result. Case-control comparison, longitudinal profiling, and cohort structure should be decided before samples enter the assay.
3. Immunoprecipitation Captures Antibody-Phage Complexes
Antibody-phage complexes are enriched by immunoprecipitation, often with Protein A/G beads or another capture reagent matched to antibody class and species. Wash conditions remove unbound or weakly associated clones while retaining phage linked to antibodies.
The output is an enriched phage pool. Quality control looks at bead chemistry, wash stringency, negative controls, input library controls, technical replicate concordance, and background binding. Loose washes can raise nonspecific binding. Harsh washes can drop weaker signals that may still matter biologically.
4. NGS Readout Identifies Enriched Peptides
DNA from enriched phage particles is amplified and sequenced. Reads are mapped back to the peptide library reference, linking each read to a clone, peptide, antigen, and annotation.
Metrics to review include sequencing depth, mapping rate, read count distribution, library coverage after immunoprecipitation, index cross-contamination checks, and batch behavior. If read depth is too low for the library complexity, rare enriched clones may be missed or become unstable across technical replicates.
5. Enrichment Analysis Converts Reads into Candidate Signals
Read counts are compared with the input library, background controls, negative controls, or comparator groups. Analysis may use fold enrichment, enrichment score, Z-score, model-based differential reactivity metrics, multiple-testing correction, and false discovery rate control.
The output is not a direct antibody concentration. It is an enrichment-based antibody-binding profile. Hits may be prioritized at the peptide, antigen, protein-region, pathway, pathogen, or cohort-signature level. Analysts also look for cross-reactivity, conserved motifs, repetitive sequences, and clones that bind nonspecifically across unrelated samples.
Assay Summary
| Step | Input | Main Output | Key Risk |
|---|---|---|---|
| Library design | Target proteome, peptidome, or antigen list | Mapped phage-displayed peptide library | Antigens absent from the library cannot be detected |
| Sample incubation | Serum, plasma, CSF, or similar material | Antibody-bound phage subset | Weak signal or matrix interference |
| Immunoprecipitation | Antibody-phage complex | Enriched phage pool | Background binding or signal loss |
| Sequencing | Enriched phage DNA | Read counts per clone | Low depth or mapping problems |
| Enrichment analysis | Read counts and controls | Candidate peptide-level reactivity | Cross-reactivity or overinterpretation |
Related Services
Main Service
Supporting Service
Validation Service
Alternative Service
Core Strengths and Current Limitations
PhIP-Seq supports broad multiplexing because many peptide-displaying clones are screened in one pooled format. That helps when sample volume is limited but the candidate antigen space is large. The peptide-level readout can support linear epitope mapping, immune exposure mapping, autoantibody discovery, and cohort-level antibody-binding profile comparison.
Library design is flexible. A study may focus on a human proteome, pathogen proteome, viral peptides, allergen sequences, tumor-associated antigens, or a custom antigen collection. The method works best when the library structure matches the biological hypothesis.
The main limitation is epitope representation. PhIP-Seq favors antibody binding to displayed peptides, often interpreted as linear epitope or peptide-level reactivity. Antibodies that require native three-dimensional folding, protein complexes, post-translational modifications, glycosylation, lipid structures, carbohydrate epitopes, or membrane context may not be captured unless the library is engineered and validated for that purpose.
Quantitation needs caution. Enrichment scores and fold enrichment reflect relative clone recovery under assay conditions. They are not calibrated ELISA concentration, antibody affinity, neutralization potency, or protective immunity. Cross-reactivity can occur when antibodies bind conserved motifs shared across proteins or organisms. Library representation bias, nonspecific binding, batch effects, and insufficient controls can also distort signals.
For teams comparing case-control sets or planning biomarker discovery, MtoZ Biolabs can review PhIP-Seq library choice, sample type, cohort structure, sequencing workflow, enrichment analysis, and validation options; researchers may submit your requirements to evaluate your project before committing limited or irreplaceable samples.
Typical Application Scenarios
Antibody Profiling Across Cohorts
A translational team may compare serum antibody-binding profiles between disease and matched control groups. PhIP-Seq fits when the antigen space is too large for a small ELISA panel. Outputs may include enriched peptides, antigen-level summaries, and group-associated signatures. Plan biological replicates, technical replicates where needed, negative controls, and batch balance.
Autoantibody Discovery
In autoimmune or inflammatory research, PhIP-Seq can screen broad human antigen libraries for candidate peptide-level reactivity. The method can point to antigens or protein regions that deserve follow-up. A single enriched peptide should not be treated as proof of disease causality. ELISA validation, peptide array validation, recombinant protein assay testing, and independent cohort replication are common next steps.
Immune Exposure Mapping and Infectious Disease Research
A pathogen-focused peptidome can show antibody-binding patterns associated with prior exposure, immune history, or longitudinal response. PhIP-Seq is useful when researchers want to compare many pathogen-derived peptides in parallel. Conserved motifs may generate cross-reactivity among related organisms, so annotation and background filtering matter.
Vaccine Response Research
PhIP-Seq may support research on peptide-level antibody recognition before and after vaccination or immunization in non-diagnostic study settings. Longitudinal profiling can show how peptide enrichment patterns shift over time. It does not directly measure neutralization or protection, so functional assays remain necessary when biological activity is the question.
Cancer Immunology and Tumor-Associated Antigen Screening
For tumor immunology projects, custom antigen libraries may include tumor-associated antigens, cancer-testis antigens, mutated peptide candidates, or selected protein regions. PhIP-Seq can identify antibody reactivity patterns that guide antigen prioritization. Study teams should decide in advance how candidate signals will be connected to tumor biology, matched controls, and orthogonal validation.
Biomarker Discovery and Hit Prioritization
PhIP-Seq can generate candidate antibody signatures for biomarker discovery, especially when researchers need broad discovery before targeted assay development. The strongest outputs come from well-matched cohort structure, multiple-testing correction, independent validation sets, and clear ranking criteria. A PhIP-Seq signature becomes more convincing only after reproducibility and assay transferability are tested.
Study Design Questions Before Starting
Before launching a PhIP-Seq study, define the antigen scope, sample matrix, comparison groups, and validation route. A human proteome library answers different questions than a viral peptidome or custom antigen library. Serum and plasma are practical for broad circulating antibody profiling. CSF needs closer review of volume, antibody abundance, and study objective.
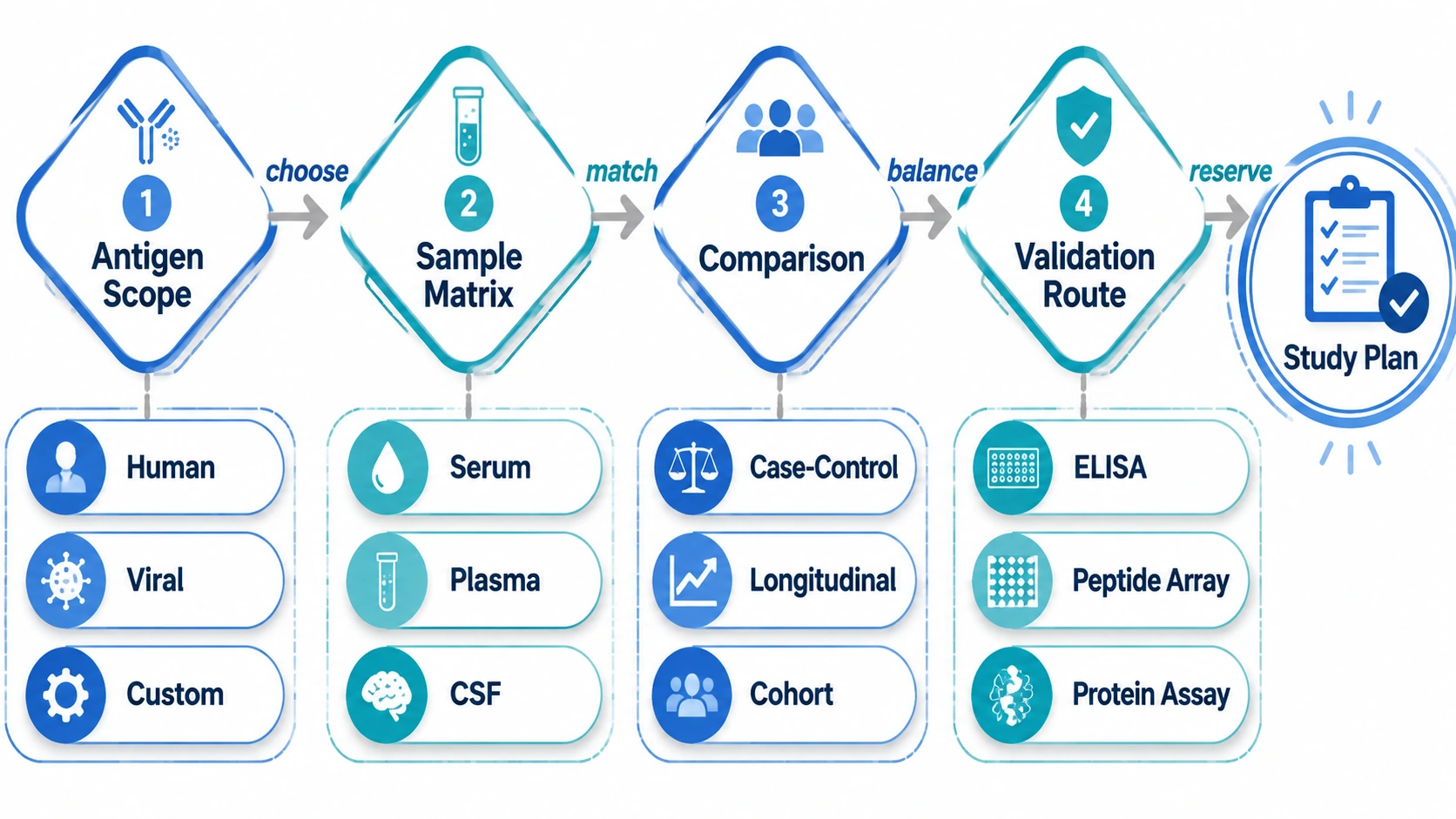
Controls shape interpretation. Input library controls show starting clone representation. Negative controls and background filters help identify nonspecific binding. Biological replicates support group-level conclusions, while technical replicates assess assay consistency. Batch planning should account for case-control balance, sequencing depth, index handling, and read mapping quality.
Set hit prioritization rules before analysis. Candidate peptides may be ranked by fold enrichment, enrichment score, false discovery rate, recurrence across samples, antigen annotation, or biological plausibility. Translational studies should reserve enough samples or an independent cohort for ELISA validation, peptide array validation, recombinant protein assay testing, or functional follow-up.
Summary and Future Outlook
PhIP-Seq is a discovery-oriented serological profiling method that links bacteriophage display, immunoprecipitation, next-generation sequencing, and enrichment analysis. Its value comes from screening broad peptide libraries and comparing peptide-level reactivity across samples. Its limits come from library design, epitope format, background binding, cross-reactivity, and semi-quantitative interpretation.
Future development will likely focus on more refined library design, improved clone representation, lower-input workflows, better batch control, richer annotation of cross-reactive motifs, and integrated analysis with proteomics, transcriptomics, clinical metadata, and targeted validation assays. Those improvements may make PhIP-Seq more informative for discovery studies, but they do not replace careful study design.
For projects involving broad antibody profiling, antigen discovery, immune exposure mapping, autoantibody research, vaccine-related studies, or biomarker screening, PhIP-Seq works best when the antigen library, sample type, cohort structure, controls, sequencing depth, enrichment statistics, and orthogonal validation plan are defined together. To discuss whether a PhIP-Seq workflow fits your sample and research question, contact MtoZ Biolabs with your antigen scope, sample matrix, comparison groups, and intended validation assays.
FAQ
Is PhIP-Seq the same as antibody sequencing?
No. PhIP-Seq sequences DNA from enriched phage clones to identify antibody-bound peptides. It does not sequence antibody receptor genes or directly reconstruct B-cell clonotypes.
Can PhIP-Seq detect conformational epitopes?
Standard PhIP-Seq libraries are better suited to linear epitope discovery than to epitopes that require native protein folding, multi-subunit structure, glycosylation, lipid context, or carbohydrate presentation.
What samples are commonly considered for PhIP-Seq?
Serum and plasma are common because they contain circulating antibodies. CSF may be considered for neuroimmune questions, but available volume and antibody abundance need feasibility review.
How should enriched peptides be interpreted?
An enriched peptide suggests antibody binding to a displayed sequence under the assay conditions. Interpretation should account for background binding, cross-reactivity, library context, cohort statistics, and antigen-region annotation.
When is ELISA better than PhIP-Seq?
ELISA is often more suitable when the antigen is already known and the goal is targeted, calibrated measurement of antibody binding to a defined antigen. PhIP-Seq is better matched to discovery across many peptide candidates.
What should be prepared before requesting a PhIP-Seq quote?
Prepare the research question, sample type, approximate sample number, case-control or longitudinal design, preferred antigen scope, available sample volume, antibody class of interest, and planned validation route. This information makes feasibility review more precise.
How to order?

