





Protein Interaction Network Analysis for Disease Research and Target Discovery
- Protein interaction network analysis is most useful when it connects experimental protein lists to pathways, complexes, disease modules, and candidate mechanisms.
- Network outputs are not proof by themselves. They generate hypotheses that need validation by mass spectrometry, co-immunoprecipitation, pull-down assays, crosslinking MS, perturbation studies, or orthogonal biology.
- The strongest projects combine high-quality protein interaction evidence, omics measurements, and biological context such as tissue type, disease stage, cell state, or treatment condition.
- Common weak points include false interactions, missing context, database bias, static network assumptions, and over-interpretation of highly connected hub proteins.
- Define the biological question, sample context, and acceptable evidence type.
- Generate or collect high-quality protein evidence, such as differential proteomics, Co-IP-MS, pull-down-MS, or curated candidate lists.
- Build the network using selected databases and document which edge types are included.
- Detect modules, hubs, enriched pathways, and condition-specific patterns.
- Validate the most important candidates with orthogonal experiments.
Protein interaction network analysis maps proteins as nodes and their functional or physical relationships as edges. For researchers working with proteomics, transcriptomics, or disease-phenotype data, the value is straightforward: a network view helps identify which proteins sit near a disease process, which modules move together, and which candidates deserve follow-up validation instead of being treated as isolated hits.
Key Takeaways
What is Protein Interaction Network Analysis?
Protein interaction network analysis is a systems biology approach for studying how proteins relate to each other within a biological process. In a typical graph, each node represents a protein, and each edge represents evidence of a relationship. That relationship may be a direct physical interaction, membership in the same protein complex, co-expression, shared pathway annotation, or a predicted functional association.
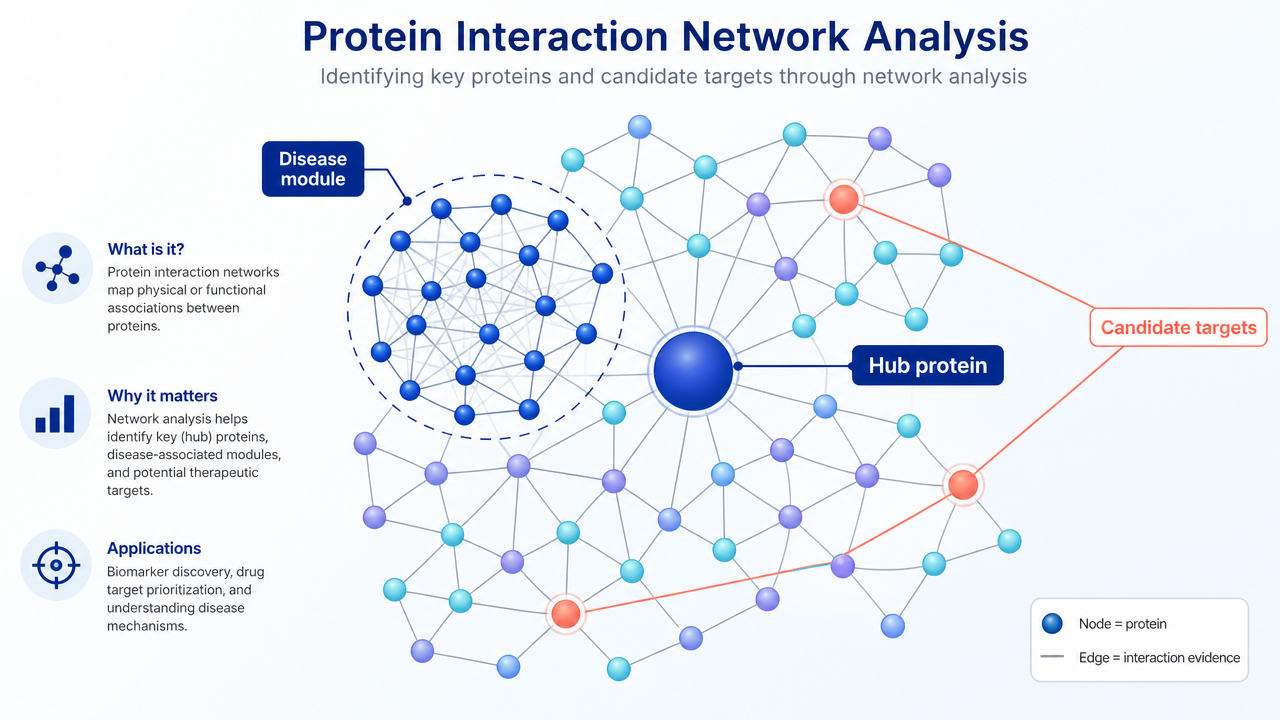
This distinction matters. A differential proteomics result may produce a list of 300 proteins, but a list does not explain biology on its own. Network analysis asks whether those proteins cluster into a signaling route, a metabolic module, a structural complex, or a disease-associated subnetwork. If they do, the researcher has a stronger starting point for mechanism work.
Related Services
Protein Interaction Network Analysis Service
MS-Based Protein Interaction Identification Service
Co-Immunoprecipitation Protein Interaction Analysis Service
Fusion Protein Interaction Analysis Service | Pull-Down and MS
Crosslinking Protein Interaction Analysis Service
Where Protein Interaction Networks Help Most?
1. Disease Mechanism Research
In disease studies, network analysis helps move from "which proteins changed?" to "which biological system may have shifted?" Cancer, neurodegeneration, immune disorders, and metabolic disease all involve coordinated protein-level changes. A network can show whether altered proteins concentrate around cell-cycle regulation, mitochondrial stress, synaptic signaling, protein degradation, extracellular matrix remodeling, or another process tied to the phenotype.
The useful output is rarely a single famous hub. It is usually a short list of connected modules and candidate regulators that fit the disease model. For example, if a tumor proteomics dataset points to a dense module around DNA damage response and chromatin regulation, those proteins become better candidates for targeted validation than proteins that changed alone and lack mechanistic connection.
2. Drug Target Discovery
Drug discovery teams use protein interaction networks to prioritize candidates by network position, disease relevance, and druggability. A target near a disease module may influence several downstream proteins. A protein complex may reveal a better intervention point than the most strongly changed protein in the dataset.
Network analysis is also useful for drug repurposing and off-target assessment. If a known drug affects proteins close to a disease module, it may justify a new hypothesis. If an intended target connects to safety-relevant pathways, the network can flag a risk before more expensive work begins.
3. Gene Function Annotation
Unknown or poorly annotated proteins can sometimes be interpreted by their neighbors. If an uncharacterized protein repeatedly appears inside a ribosome biogenesis module, an endoplasmic-reticulum stress module, or a mitochondrial translation module, its network context gives a testable functional hypothesis.
This is not a shortcut around validation. It is a way to choose the right validation. Instead of testing every possible function, the researcher can design assays around the module where the protein sits.
4. Multi-Omics Integration
Protein interaction networks become more informative when mapped with quantitative data. Transcriptomics can show upstream expression shifts. Proteomics can show protein abundance. Phosphoproteomics can reveal signaling activity. Metabolomics can show downstream biochemical effects. A network provides the scaffold that helps these layers talk to each other.
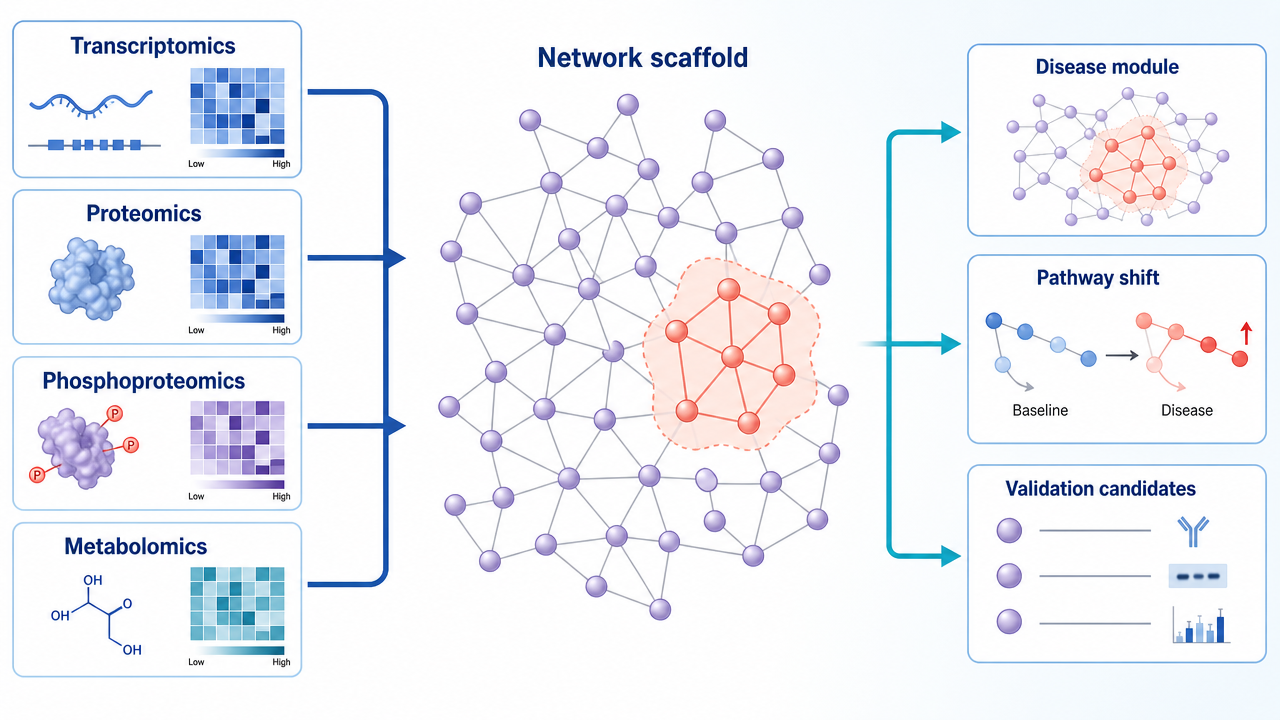
For example, a protein may not change in abundance, but its phosphorylated form may shift sharply after treatment. Network analysis can place that signaling event near interacting proteins and pathway neighbors, which helps explain why an abundance-only analysis missed the key biology.
Main Benefits
The first benefit is prioritization. Modern omics experiments often produce too many candidates for direct follow-up. Network analysis narrows the field by highlighting connected proteins, recurrent modules, and high-value candidates.
The second benefit is biological interpretation. A pathway enrichment table can tell you that a pathway is statistically overrepresented. A network can show which proteins create that signal, how they connect, and whether they form one coherent module or several unrelated clusters.
The third benefit is integration. Protein interaction networks can combine public interaction databases, project-specific mass spectrometry data, phenotype labels, and pathway knowledge. When the inputs are reliable, this creates a more grounded interpretation than any single data layer alone.
Main Limitations
Network analysis depends heavily on evidence quality. Public interaction databases contain a mixture of direct physical interactions, predicted associations, literature-curated edges, and high-throughput screening results. Treating all edge types as equal can produce confident-looking but fragile conclusions.
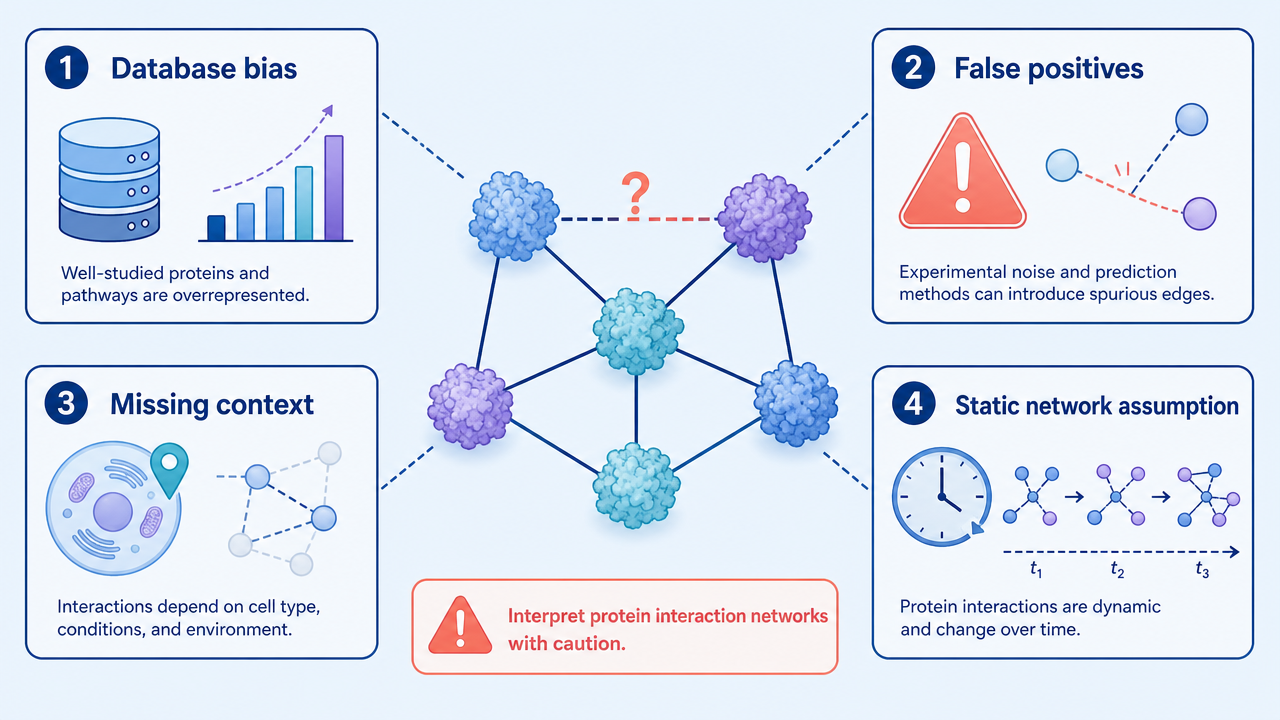
Context is the second problem. Many networks are static, while real protein interactions depend on cell type, localization, time, stimulation, post-translational modification, and disease state. A protein that interacts in one cell system may not interact in another.
Hub proteins also need caution. Highly connected proteins often look important because they are well studied or technically easy to detect. Some are genuinely central. Others are database magnets. A good analysis checks whether a hub makes sense in the sample context and whether the supporting evidence is direct enough for the claim being made.
How to Choose a Protein Interaction Strategy?
Different questions require different evidence. If the goal is to explore a broad disease module, database-guided network analysis plus quantitative proteomics may be appropriate. If the goal is to identify binding partners for a bait protein, Co-IP-MS or pull-down-MS is closer to the biology. If the goal is to support direct proximity or contact information, crosslinking MS can add structural constraints.
| Research question | Better starting point | What it can answer | Main caution |
|---|---|---|---|
| Which pathways are connected to my protein list? | Network analysis with curated PPI databases | Module structure and candidate regulators | Database bias and indirect edges |
| What proteins bind my bait protein? | Co-IP-MS or pull-down-MS | Candidate physical interaction partners | Non-specific binders and lysis artifacts |
| Which interactions change between conditions? | SILAC Co-IP-MS or quantitative interaction proteomics | Condition-dependent interaction shifts | Requires careful controls and replication |
| Are two proteins close enough for structural inference? | Crosslinking MS | Spatial restraints and complex architecture | Crosslink coverage can be incomplete |
| Which network candidates should be validated? | PRM, targeted MS, Western blot, perturbation assays | Candidate confirmation | Validation design must match the hypothesis |
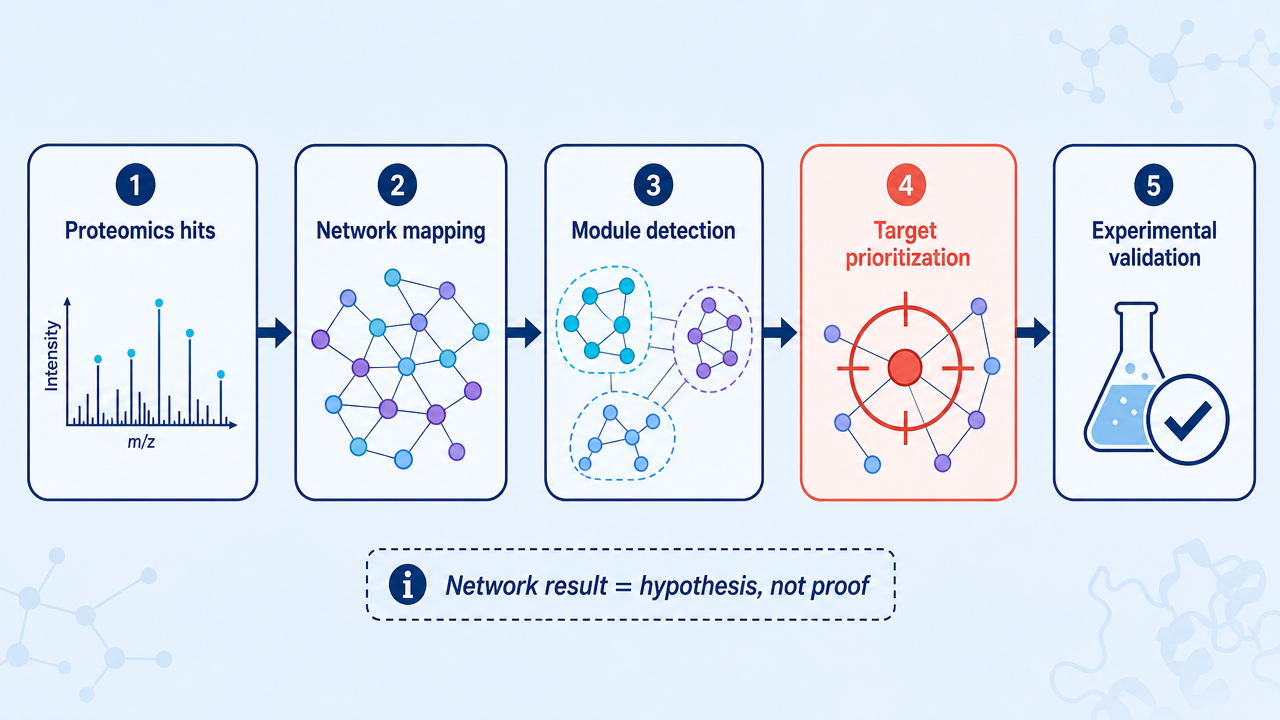
Practical Workflow
A robust protein interaction network project usually follows five steps:
The last step is the one that keeps the analysis honest. A clean network figure can be persuasive, but validation determines whether the model survives contact with biology.
FAQ
1. What is protein interaction network analysis used for?
Protein interaction network analysis is used to interpret protein lists, identify disease-associated modules, prioritize drug targets, annotate protein function, and integrate multi-omics data. It helps researchers see whether proteins connect through pathways, complexes, or regulatory neighborhoods.
3. Is a protein interaction network the same as a protein-protein interaction assay?
No. A network analysis is a computational interpretation of protein relationships. A protein-protein interaction assay, such as Co-IP-MS, pull-down-MS, or crosslinking MS, generates experimental evidence for interactions or proximity. Strong projects often use both.
3. Can protein interaction network analysis prove a disease mechanism?
Not by itself. It can suggest a mechanism and prioritize candidates, but disease mechanisms require experimental validation. The network is a map for choosing what to test next.
4. What data is needed for protein interaction network analysis?
Common inputs include differentially expressed proteins, proteomics results, phosphoproteomics data, candidate genes, known PPI databases, pathway annotations, and phenotype labels. The best input set depends on the biological question.
5. Why do protein interaction networks sometimes give misleading results?
They can be misleading when edges come from weak evidence, when the network lacks cell-type or disease context, when highly studied proteins dominate the graph, or when indirect functional associations are interpreted as direct binding events.
Conclusion
Protein interaction network analysis is most valuable when it turns large protein datasets into testable biological hypotheses. It can point to disease modules, candidate targets, and pathway-level mechanisms, but it should not be treated as a final answer. The best use is practical: build the network carefully, interpret it in context, and validate the proteins that matter most for the research question.
How to order?

