





DDA in Proteomics: Data-Dependent Acquisition Explained
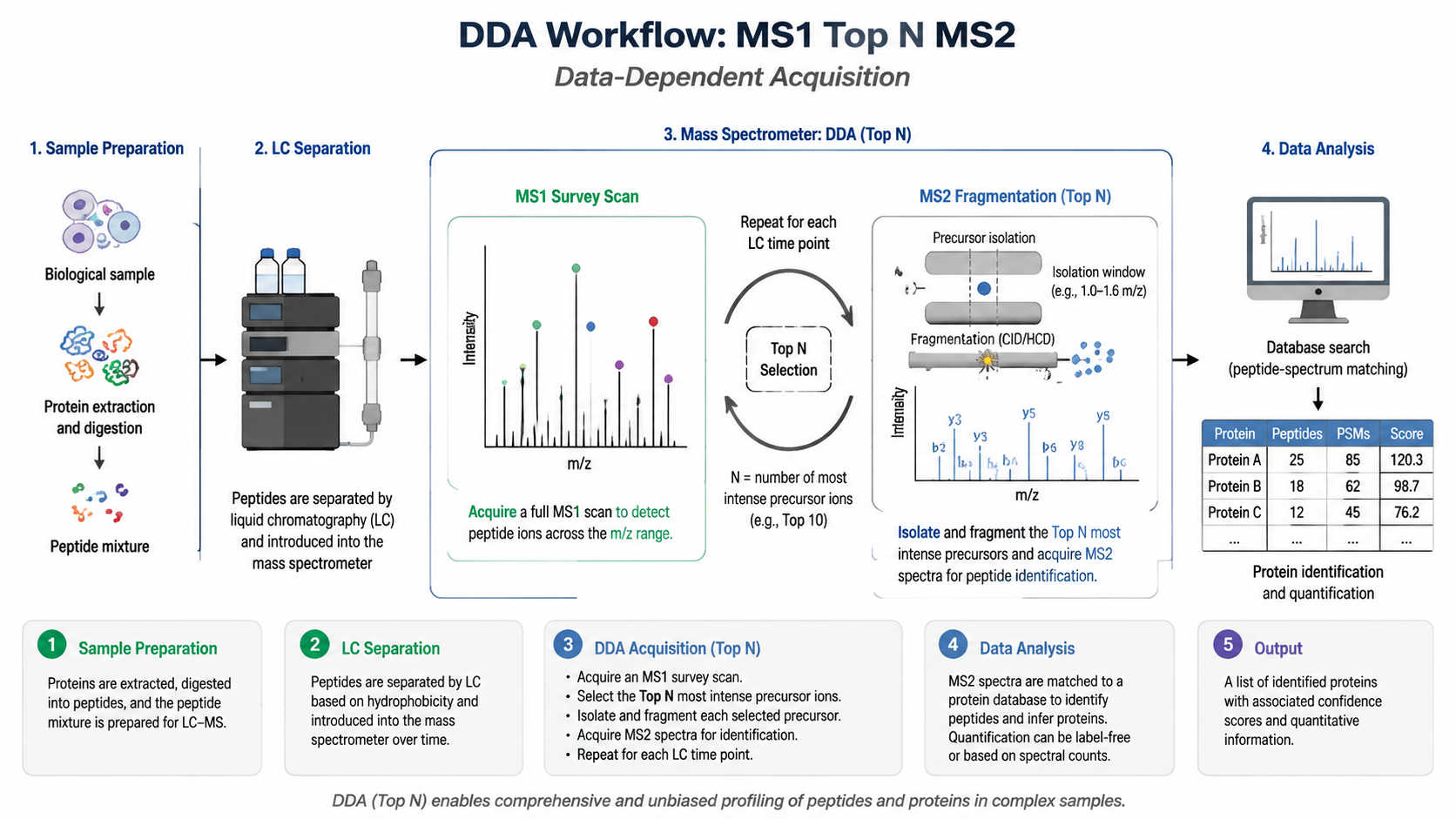
- MS1 survey → Top N selection → isolated MS2 → database search.
- DDA spectra are clean and work with established search engines.
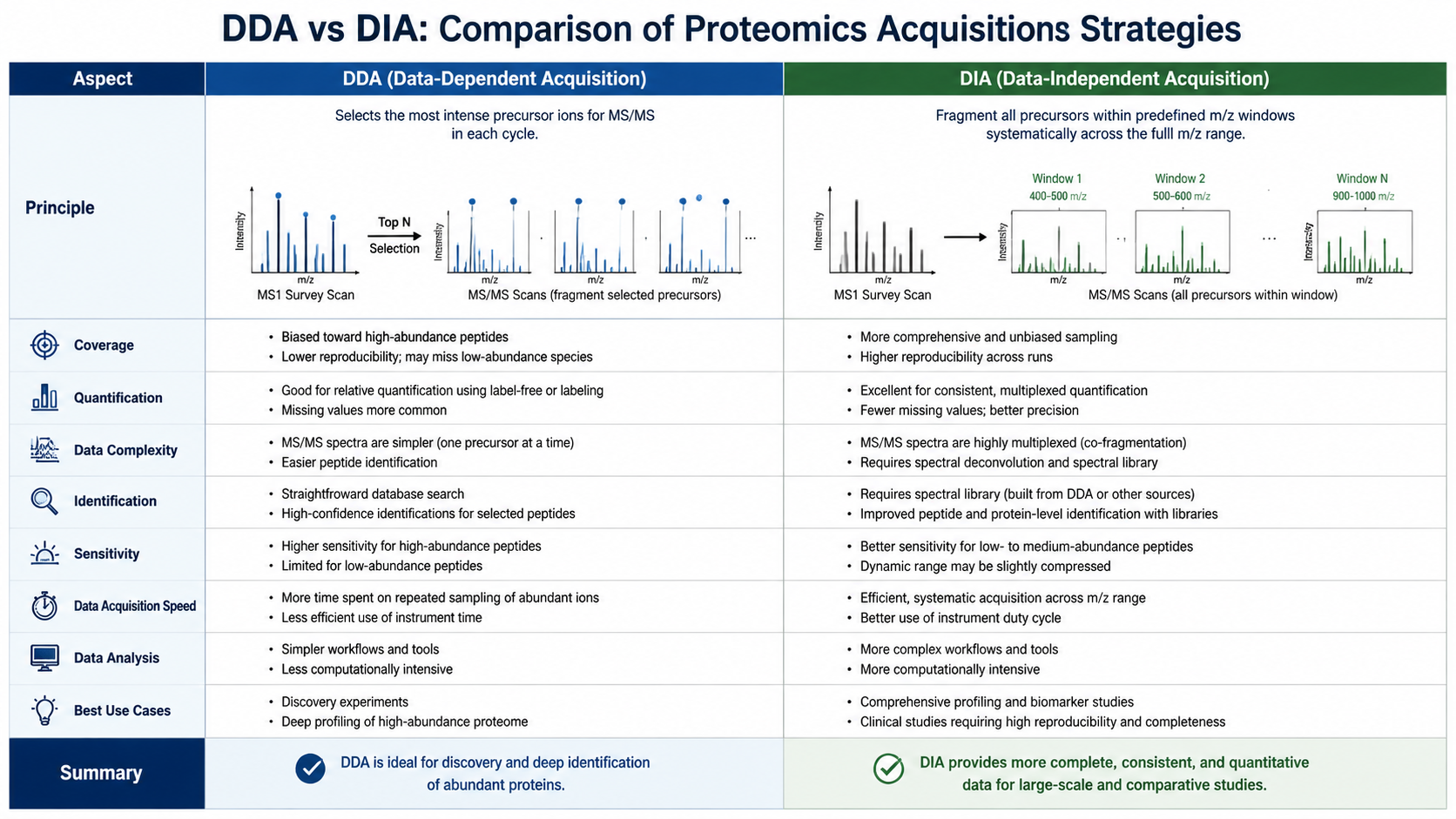
- Abundance bias and stochastic sampling limit cohort reproducibility.
- DDA and DIA are complementary: libraries from DDA scale with DIA.
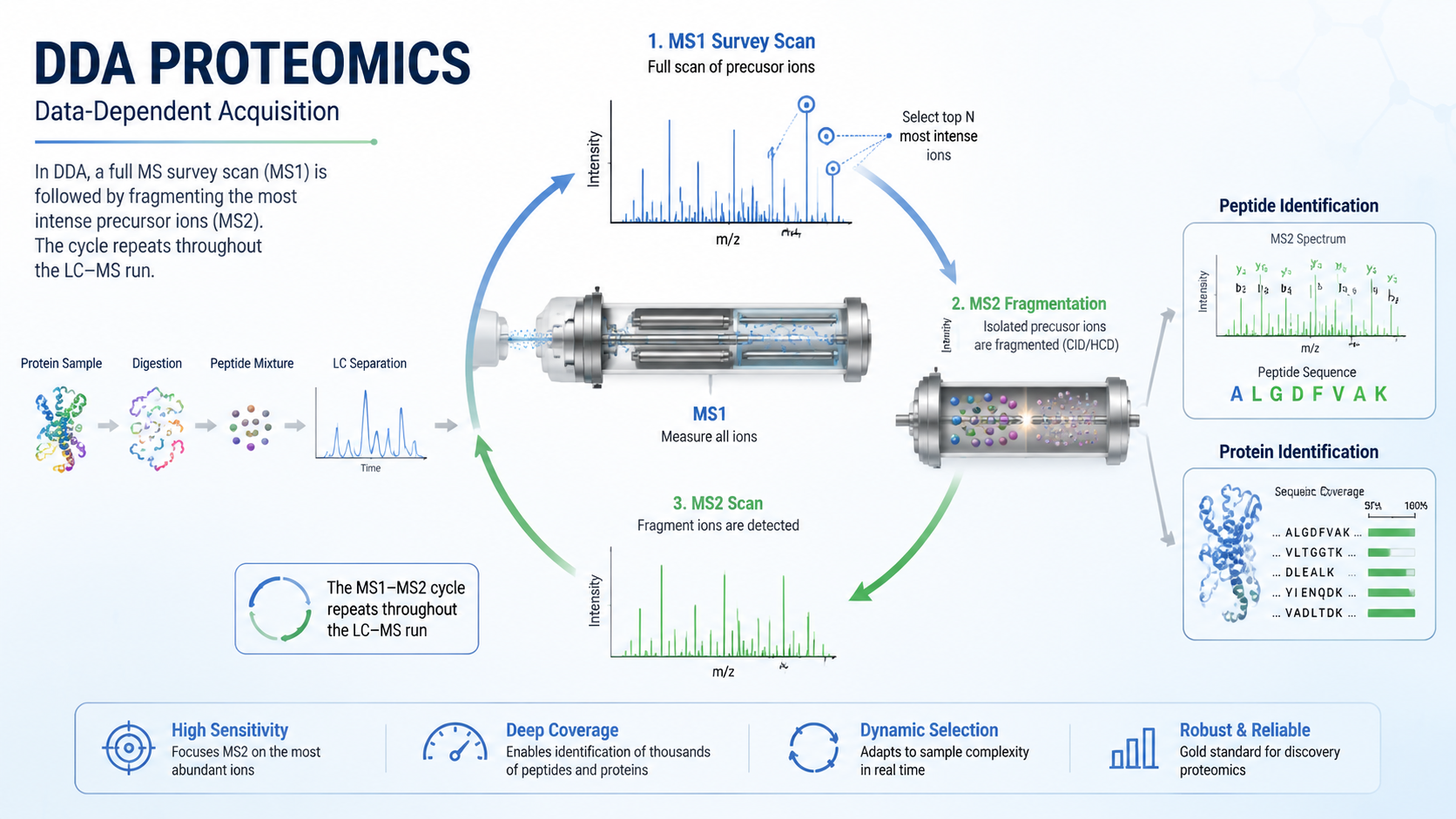
Data-dependent acquisition (DDA) triggers MS2 on precursors chosen from each MS1 survey, typically Top N by intensity, making it a core strategy for peptide identification and DIA spectral library generation.
Key Takeaways
Related Services
Protein Identification by LC-MS/MS Service
Protein Identification Service by Shotgun Proteomics
Qualitative Proteomics Analysis Service
4D-DIA Quantitative Proteomics Service
FAQ
1. What is Top N?
The N most intense precursors selected for MS2 after each MS1 scan.
2. Is DDA still used?
Yes. For discovery, libraries, and high-confidence MS/MS-driven identification.
3. How does DDA support DIA?
DDA experiments often build or extend spectral libraries used in DIA searches.
Conclusion
DDA is not replaced by DIA; the two modes address different stages of discovery and quantification workflows.
How to order?

