





Resources
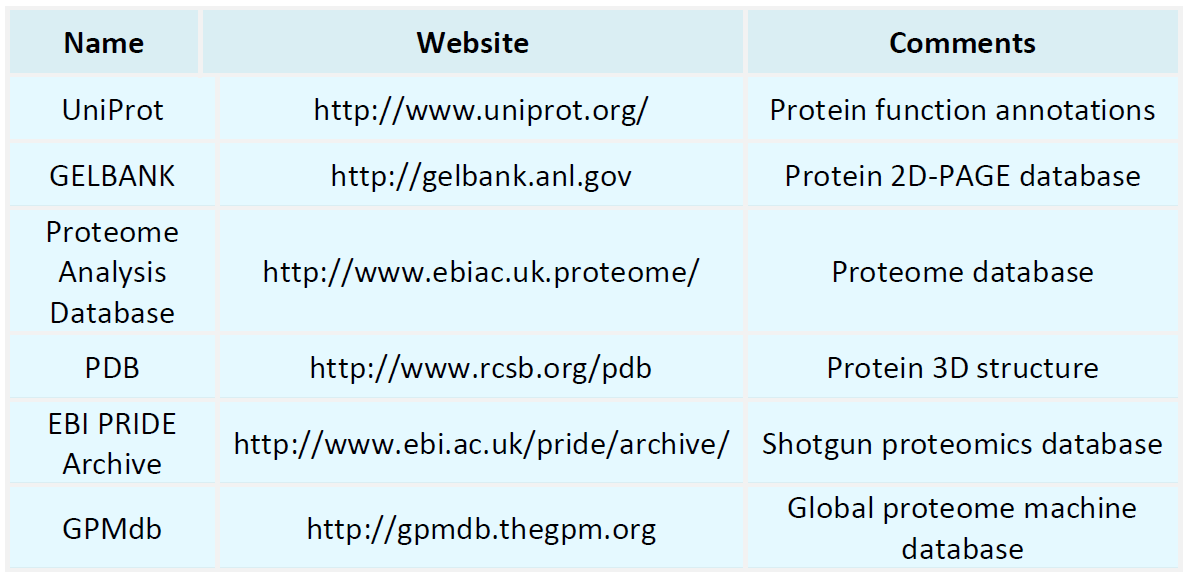
Proteomics Databases
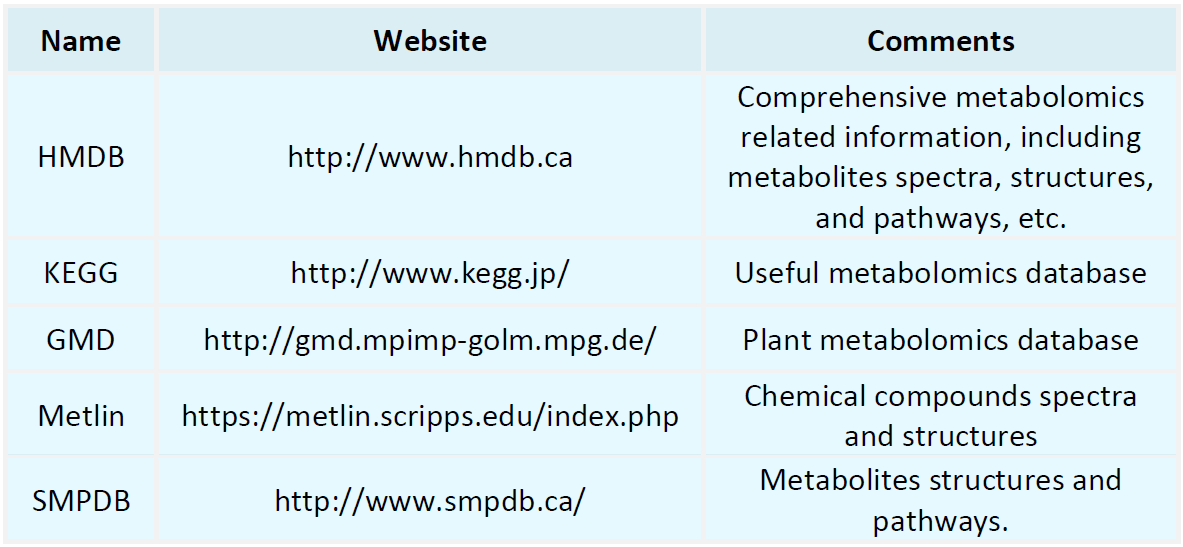
Metabolomics Databases
-
• Mechanisms of iTRAQ, TMT, and SILAC in Protein Quantification
With the rapid advancement of proteomics, quantitative proteomics techniques have been widely applied in biological research. iTRAQ (Isobaric Tags for Relative and Absolute Quantitation), TMT (Tandem Mass Tags), and SILAC (Stable Isotope Labeling by Amino Acids in Cell Culture) are three commonly used methods for protein quantification, each with its unique advantages and applications.
-
• Applications of iTRAQ, TMT, and SILAC in Protein Quantification
In proteomics research, the precise quantification of proteins in complex biological samples is a critical objective. To achieve this, several labeling technologies have been developed, including iTRAQ (Isobaric Tags for Relative and Absolute Quantification), TMT (Tandem Mass Tags), and SILAC (Stable Isotope Labeling with Amino Acids in Cell Culture).
-
• Workflows of iTRAQ, TMT, and SILAC in Protein Quantification
Protein quantification is crucial for understanding cellular functions, disease mechanisms, and biological system complexities in proteomics research. iTRAQ (Isobaric Tags for Relative and Absolute Quantification), TMT (Tandem Mass Tag), and SILAC (Stable Isotope Labeling by Amino acids in Cell culture) are three widely used quantitative proteomics methods. Each method has unique advantages and is extensively applied in relative or absolute protein quantification.
-
• Advantages and Disadvantages of iTRAQ, TMT, and SILAC in Protein Quantification
In proteomics research, quantitative analysis is a crucial tool for uncovering protein expression levels, molecular regulatory mechanisms, and cellular signaling pathways. iTRAQ, TMT, and SILAC are three commonly used protein quantification techniques.
-
• Principles of iTRAQ, TMT, and SILAC in Protein Quantification
Protein quantification plays a crucial role in modern life sciences research. By quantifying the relative or absolute abundance of proteins, researchers can gain deep insights into changes in protein expression profiles under different conditions, and how these changes contribute to diseases, development, or environmental responses.
-
• Analysis of Antibody Sequences Using Mass Spectrometry
Antibodies play a crucial role in biomedical research and clinical applications. Accurate antibody sequence analysis is essential for antibody engineering, drug development, and immunotherapy. In recent years, mass spectrometry (MS) has become a powerful tool for antibody sequence analysis due to its high sensitivity, high resolution, and high throughput.
-
• Procedure of Top-Down Protein Sequencing for Modified Terminals
Top-down protein sequencing is a powerful mass spectrometry-based approach used to analyze intact proteins without the need for enzymatic digestion. This method provides a comprehensive view of protein modifications, including those at the N- and C-terminal ends, which are critical for understanding protein function and regulation.
-
• Analysis of Monoclonal Antibodies Using De Novo Sequencing
Monoclonal antibodies (mAbs) are antibodies produced by a single B cell clone, known for their high specificity and consistency. They have become crucial in therapeutic, diagnostic, and research applications.
-
• Detection of Protein Modifications by Top-Down Sequencing
Proteins are the primary agents of life activities, performing a wide range of functions such as catalyzing biochemical reactions, providing structural support, and transmitting signals. The functionality of a protein is determined not only by its amino acid sequence but also by its post-translational modifications (PTMs). PTMs refer to the chemical alterations that occur after protein synthesis, modifying its properties and functions.
-
• Procedure for Peptide Sequencing Based on De Novo Method
In proteomics research, peptide sequencing is a crucial technique for understanding protein structure and function. Unlike traditional database search methods, De Novo sequencing does not rely on known protein sequence databases but directly derives amino acid sequences from mass spectrometry data.
How to order?

