





How PhIP-Seq Works for Antibody Repertoire Profiling
Introduction
Antibody repertoire profiling becomes difficult when a research question moves beyond one known antigen. A patient serum sample, vaccine cohort, autoimmune panel, or infection-history study may contain thousands of antibody specificities. Conventional assays can test selected antigens, but broad immune recognition requires a higher-throughput view of antibody binding.
PhIP-Seq antibody repertoire profiling links antibody binding with next-generation sequencing. Antibody-containing samples are exposed to a phage display peptide library. Antibodies pull down phage clones that display recognized peptides, and sequencing reads identify which peptides were enriched. The result is not a full B-cell receptor repertoire. It is a functional map of antibody reactivity against the peptide space represented in the library.
For teams planning serum antibody profiling, infectious disease serology, vaccine response analysis, or epitope discovery, the key question is whether the library, samples, controls, and analysis strategy match the biological question. MtoZ Biolabs can review project design before sample-limited cohorts are committed to a full PhIP-Seq run.
Related Services
| Research Need | Recommended Service |
| Need broad antibody reactivity profiling from serum or plasma | PhIP-Seq Antibody Analysis Service |
| Need peptide-level epitope discovery after screening | Antibody Epitope Mapping Service |
| Need targeted validation of candidate peptide regions | Peptide Array-Based Epitope Mapping Service |
| Need broader peptide epitope screening support | High-Throughput Peptide Epitope Mapping Service |
Figure 1. PhIP-Seq converts serum antibody binding into sequencing-based peptide enrichment data.
What PhIP-Seq Measures in an Antibody Repertoire
PhIP-Seq does not sequence antibodies directly. Instead, it measures the peptide targets that antibodies recognize. This distinction matters. B-cell receptor sequencing describes antibody gene diversity at the nucleotide level. PhIP-Seq describes functional binding patterns across a defined peptide library. Both approaches can be valuable, but they answer different questions.
In antibody repertoire profiling, the term "repertoire" refers to the collection of antibody reactivities present in a sample. A serum sample may contain antibodies from past infections, vaccination, autoimmune activity, tumor-associated immune responses, or environmental exposure. PhIP-Seq screens many peptide antigens in parallel and identifies enriched peptides associated with samples or groups.
The output is usually an enrichment matrix. Rows represent peptides or peptide groups, and columns represent samples. Each value reflects how strongly a peptide was enriched after immunoprecipitation compared with input, negative controls, or background models. This matrix supports clustering, differential enrichment, candidate epitope selection, and validation planning.
Core Principle: Display, Capture, Sequence, Map
The core PhIP-Seq workflow has four technical ideas. First, a phage display peptide library presents many peptide sequences on phage particles. The library may represent viral proteomes, human proteome fragments, pathogen panels, allergens, tumor antigens, or custom peptide designs.
Second, antibody-containing samples are incubated with the library. Antibodies bind phage- displayed peptides that resemble recognized epitopes. The interaction may reflect linear epitopes, motif-like recognition, or cross-reactive peptide features. Because the library is peptide- based, conformational epitopes may be missed unless a relevant linear motif is represented.
Third, antibody-bound phage are captured by immunoprecipitation. Magnetic beads or capture reagents pull down antibody-phage complexes. Wash steps reduce nonspecific binding, while elution and amplification prepare recovered phage DNA for sequencing. Sample quality, bead chemistry, incubation, and wash stringency strongly affect the final signal.
Fourth, sequencing reads are mapped back to peptide identities. Enriched peptide sequences are quantified and compared across controls, replicates, and sample groups. Analysis should account for input distribution, sequencing depth, background binding, and multiple testing. Without these controls, a high read count can be mistaken for meaningful antibody reactivity.
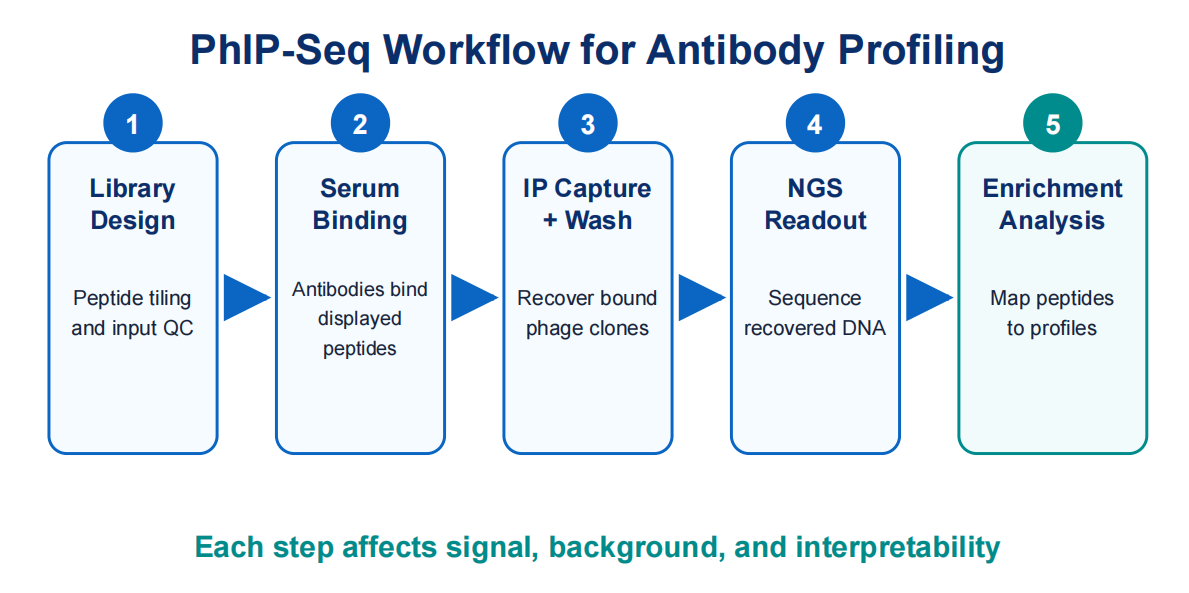
Figure 2. A typical workflow moves from peptide library design to antibody binding, immunoprecipitation, sequencing, and enrichment analysis.
Step 1: Library Design Defines the Search Space
The peptide library determines what PhIP-Seq can and cannot detect. A viral peptide library can support exposure history or infection-response studies. A human proteome library can support autoantibody discovery. A custom library can focus on proteins, variants, or domains linked to a specific hypothesis. The library should be chosen before sample submission, not after data analysis begins.
Library design considers peptide length, tiling density, overlap, antigen source, sequence redundancy, and expected epitope type. Shorter peptides can increase resolution but may miss longer motifs. Longer peptides preserve more context but reduce fine mapping precision. Dense tiling improves localization, while sparse tiling reduces cost and complexity.
Representation is also critical. If a peptide clone is underrepresented in the input library, weak enrichment may be hard to detect. If some clones dominate the starting pool, reads may reflect library imbalance rather than antibody binding. Good PhIP-Seq antibody repertoire profiling starts with library QC, input normalization, and enough representation to avoid bottlenecks.
Step 2: Sample and Control Design Shape Interpretation
Serum and plasma are common inputs because circulating antibodies are accessible and stable when handled correctly. Other antibody-containing fluids may be possible, but matrix effects, antibody abundance, and background binding should be evaluated. Repeated freeze-thaw cycles, hemolysis, contamination, or inconsistent storage can create technical noise.
Controls are not optional in PhIP-Seq. A no-serum control helps estimate bead and phage background. Healthy or baseline controls help define cohort-level background reactivity. Technical replicates show whether enrichment is reproducible. Positive controls, when available, confirm that expected antibody-peptide interactions can be recovered.
Cohort design should match the hypothesis. A vaccine study may compare baseline and post- vaccination time points. An autoimmune study may compare disease and matched control groups. An infection-history study may need exposure-confirmed samples. Poorly defined groups can make biological interpretation fragile even when data are generated.
Step 3: Immunoprecipitation Converts Binding into Enrichment
Immunoprecipitation is the experimental bridge between antibody binding and sequencing readout. Antibody-library incubation allows serum antibodies to bind displayed peptides. Capture reagents then recover the antibody-bound phage. Washes remove nonspecific material, and recovered phage DNA is sequenced.
This step must balance sensitivity and specificity. Mild conditions may preserve weak interactions but increase background. Harsh conditions may reduce nonspecific binding but lose low-affinity or low-abundance binders. The optimal condition depends on the library, sample type, antibody class, and study goal.
For broad serum antibody repertoire profiling, the workflow should preserve diversity while controlling nonspecific carryover. For focused epitope mapping, stronger stringency may be useful because the goal is to distinguish candidate peptide regions. If serum volume is limited or the expected signal is weak, MtoZ Biolabs can help plan a pilot before scaling the cohort.
Step 4: Sequencing and Enrichment Analysis Build the Profile
After immunoprecipitation, recovered phage DNA is amplified and sequenced. Reads are assigned to peptide identities using the library reference. The basic output is a count table, but count data alone are not enough. Analysis usually normalizes for sequencing depth, library input, background enrichment, and replicate behavior.
Enrichment analysis asks which peptides are overrepresented after antibody capture. A peptide may be interpreted alone, as part of an overlapping tiled region, or as a member of a protein or pathogen group. Stronger interpretation comes from consistent enrichment across neighboring peptides, replicates, or defined groups.
Data visualization can include heatmaps, differential enrichment plots, peptide coverage tracks, clustering plots, and sample similarity maps. These views help identify immune recognition patterns, candidate epitopes, cross-reactive motifs, and outlier samples.
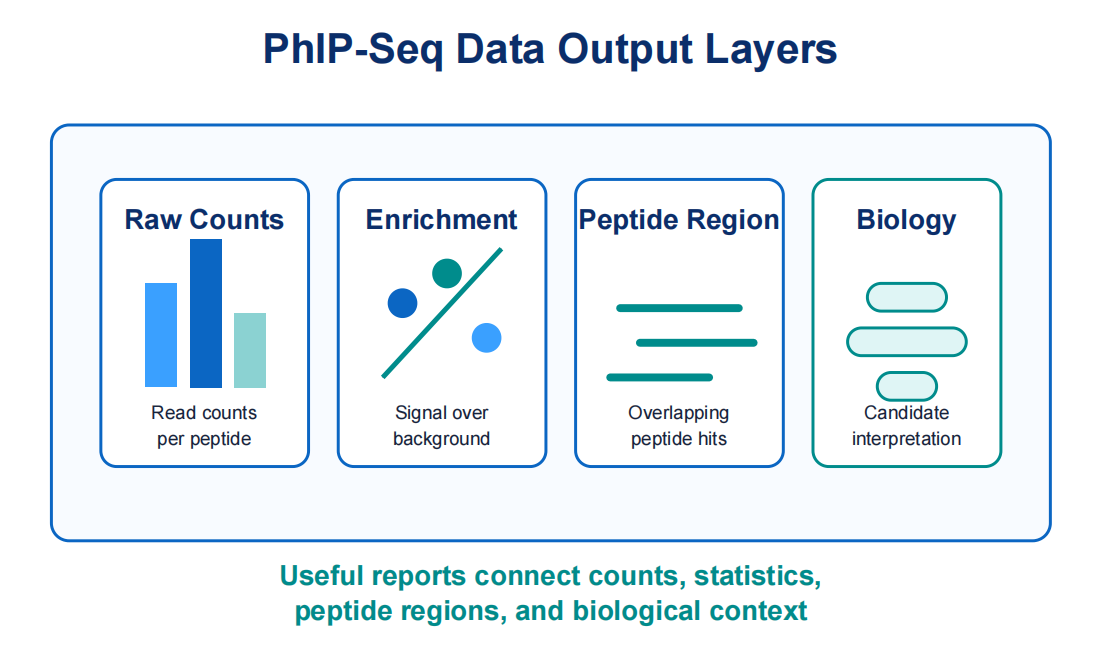
Figure 3. Strong PhIP-Seq deliverables connect raw counts with enrichment statistics, peptide regions, and biological interpretation.
Strengths and Technical Limitations
The main strength of PhIP-Seq is scale. A single experiment can evaluate antibody reactivity across thousands to millions of peptide sequences, depending on library design. This helps when researchers do not know which antigen targets matter at the start.
Another strength is sequence-level interpretability. Enriched peptides can point to candidate epitopes, conserved motifs, pathogen proteins, or autoantigen regions. This is more specific than a broad positive or negative assay result.
However, PhIP-Seq has important limitations. Peptide libraries are best suited for linear or motif- like epitopes. Conformational epitopes, glycan-dependent recognition, lipid antigens, or structure- dependent binding may not be represented. A peptide that is absent, underrepresented, or poorly displayed cannot be recovered with confidence.
The method is also sensitive to background. Some phage clones may bind nonspecifically to beads, capture reagents, or sample matrix components. Some peptides may appear enriched because of amplification bias. Controls and statistical filtering are core method elements, not optional cleanup.
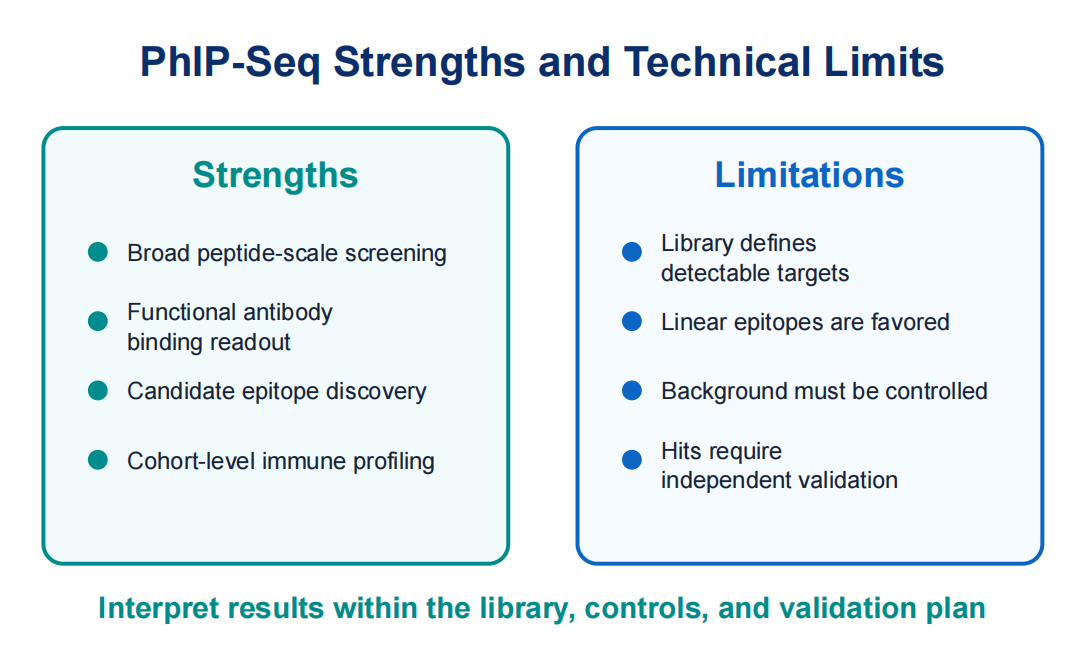
Figure 4. PhIP-Seq provides broad peptide-level profiling, while interpretation remains constrained by library design, epitope type, and background control.
Typical Applications
In infectious disease research, PhIP-Seq can profile antibody reactivity against viral, bacterial, or parasitic peptide libraries. This supports exposure history studies, immune response tracking, and identification of peptide regions linked to infection or disease stage.
In vaccine research, the method can compare antibody profiles before and after immunization. It can help identify immunodominant peptide regions, monitor response breadth, and compare formulations. Results should be interpreted with neutralization, binding, or functional assays when protection is the final question.
In autoimmune research, human proteome or disease-focused libraries can support autoantibody discovery. Enriched peptides may point to candidate autoantigens, disease- associated motifs, or subgroup-specific immune patterns. Because autoantibody signals can be heterogeneous, cohort design and validation are critical.
In biomarker discovery, PhIP-Seq can generate candidate antibody-reactive peptides for follow-up testing. Discovery results should be validated with peptide arrays, ELISA, Western blotting, or targeted immunoassays before being used as diagnostic or mechanistic evidence.
What a Useful PhIP-Seq Report Should Include
A useful report should include more than a ranked peptide list. Researchers should expect library design, sample handling, controls, sequencing depth, read mapping, enrichment calculation, replicate quality, and candidate interpretation. If the report lacks QC context, it is difficult to know whether a peptide signal is biological or technical.
For publication-oriented or translational studies, the report should connect results to the study question. This may include group-level comparisons, annotated peptide regions, protein summaries, pathogen context, and validation recommendations. The goal is not the longest hit list. The goal is interpretable candidates for the next experiment.
Frequently Asked Questions
1. Does PhIP-Seq sequence the antibody repertoire?
No. PhIP-Seq profiles antibody binding against a peptide library. It does not recover antibody heavy-chain or light-chain sequences.
2. What sample types are commonly used?
Serum and plasma are common because they contain circulating antibodies. Other fluids may be considered, but suitability depends on antibody abundance, matrix effects, and the study goal.
3. Can PhIP-Seq identify conformational epitopes?
Usually not directly. PhIP-Seq peptide libraries are strongest for linear epitopes or motif-like recognition. Structure-dependent epitopes require orthogonal methods.
4. How should PhIP-Seq hits be validated?
Important candidate peptides should be validated with peptide arrays, ELISA, Western blotting, or targeted immunoassays. Validation design should match the final use.
5. What determines data quality?
Data quality depends on library design, sample handling, immunoprecipitation efficiency, sequencing depth, controls, replicate consistency, and statistical filtering.
Conclusion
PhIP-Seq antibody repertoire profiling converts antibody-peptide binding into sequencing-based enrichment data. The method can screen broad peptide libraries and reveal functional antibody recognition patterns across samples, cohorts, or disease states. Its value depends on the match between the biological question, library design, sample quality, controls, and validation.
For teams planning serum antibody profiling, epitope discovery, vaccine response studies, or antibody biomarker screening, a well-designed PhIP-Seq study can reduce uncertainty before validation begins. To evaluate whether a library strategy, sample set, and control plan fit your project, contact MtoZ Biolabs for technical review before full-scale profiling.
How to order?

