





De Novo Sequencing vs Database Search: Which Approach Fits Your Study?
-
the sample background is complex but one protein region is sequence-critical
-
an antibody or biologic must be confirmed against an expected construct
-
a variant peptide is suspected but not present in the reference database
-
environmental or microbiome samples contain a mixture of annotated and unannotated organisms
-
Does a reliable reference proteome exist for this sample source?
-
Could the true sequence differ because of engineering, mutation, or poor annotation?
-
Is the main goal identification coverage or sequence confirmation?
-
How many spectra or proteins truly require manual sequence review?
-
Will the final report support cloning, publication, QC, or regulatory use?
Introduction
Most proteomics labs use reference-based search as the default route for protein identification. The method is efficient, scalable, and well supported by software pipelines when a high-quality reference proteome is available. However, many studies do not fit that assumption. A sample may come from a poorly annotated species, a proprietary expression system, an engineered antibody, or a protein with an unexpected sequence variant. In those cases, researchers must decide whether reference matching is still sufficient or whether de novo sequencing is required to recover the true peptide sequence.
The choice is not simply about which method is more advanced. Reference-based search and sequence-from-spectrum analysis answer different questions. Database search asks which known sequence best explains an MS/MS spectrum. De novo sequencing asks what sequence the spectrum itself supports. Selecting the wrong approach can waste instrument time, produce false confidence, or miss the biologically important peptide entirely.
Related Services
| Research Need | Recommended Service Direction |
| Derive sequence without a reliable database match | De Novo Sequencing Service |
| Confirm protein sequence by mass spectrometry | De Novo Protein Sequencing Service |
| Identify proteins in standard annotated proteomes | Mass Spectrometry-Based Protein Identification Service |
| Sequence unknown or poorly annotated proteins | Unknown Proteins Sequencing Service |
| Support broader MS sequence and mapping workflows | Protein Sequencing Service by Mass Spectrometry |
For studies where the best approach is unclear, MtoZ Biolabs can help evaluate whether reference matching, sequence-from-spectrum analysis, or a hybrid workflow best matches the sample type, reference availability, and reporting goal.
When Researchers Face This Decision
The comparison usually appears at a specific decision point. A reference-based search may return no confident peptide match for an important gel band. A recombinant protein may show peptide evidence that does not fully align with the expected construct. An antibody project may need variable-region sequence when hybridoma transcript data are incomplete. A metaproteomics or environmental sample may contain proteins from organisms with limited genomic annotation.
In each case, the practical question is the same: does the study need to match known references, or does it need to discover sequence that the database does not contain? That question should be answered before committing MS time, digestion design, and data analysis strategy.
Four Comparison Dimensions That Matter Most
A useful comparison should focus on decision-relevant differences rather than generic method descriptions. Four dimensions matter most for most proteomics projects: reference availability, study goal, throughput needs, and required level of sequence certainty.
1. Reference Availability
Reference-based search depends on a suitable sequence database. If the organism, isoform, engineered tag, fusion region, or mutation is absent from the reference, peptide-spectrum matching becomes weak or misleading. Sequence-from-spectrum analysis is designed for cases where the correct sequence cannot be assumed in advance.
2. Study Goal
Discovery proteomics on well-annotated samples favors reference matching. Unknown protein identification, antibody sequencing, variant confirmation, and biopharmaceutical sequence verification often require the de novo route or a hybrid strategy.
3. Throughput and Scale
Reference-based search is better suited to large-scale identification across many samples and deep proteomes. The de novo route is more labor-intensive and is usually targeted to unmatched spectra, enriched proteins, or sequence-critical regions.
4. Sequence Certainty
Reference matching can confidently identify peptides that match known entries. Sequence-from-spectrum analysis can reveal novel or divergent sequence but often requires manual spectrum review, replicate support, and overlap validation for high-confidence peptide identification.

Figure 1. Core differences between reference-based search and sequence-from-spectrum analysis
How Database Search Performs in Practice
Reference-based search matches experimental MS/MS spectra to in silico fragment ions generated from a protein sequence database. The method works best when the database is complete, current, and specific to the sample source. Search engines score peptide-spectrum matches using mass accuracy, enzyme specificity, fragment coverage, and false discovery rate control.
The approach is the right first choice for many proteomics studies because it is fast, scalable, and statistically mature. It supports protein identification across complex samples, quantitative workflows, and post-translational modification searches when the underlying protein sequence is known. For model organisms, human samples, and standard cell-line proteomes, reference matching remains the most efficient route to protein identification.
The main weakness appears when the reference is wrong or incomplete. A missing isoform, undocumented mutation, expression construct difference, or cross-species homology gap can prevent a valid spectrum from receiving a confident match. In those cases, the problem is not poor MS data. The problem is that the database does not contain the sequence being measured.
How De Novo Sequencing Performs in Practice
The method derives peptide sequence from the MS/MS spectrum itself. Fragment ions are interpreted as residue-level mass differences, and candidate sequences are assembled without requiring a prior database match. This makes the method valuable for unknown proteins, engineered biologics, antibody variable regions, venoms, environmental samples, and any project where the measured sequence may differ from public references.
The de novo route is strongest when spectra are high quality and the target material is enriched. It is weaker when spectra are sparse, mixtures are complex, or reporting standards require rapid high-throughput identification across an entire proteome without manual review. The method is therefore often used selectively rather than as a replacement for all reference-matching steps.
In many successful projects, de novo analysis is applied after reference search fails or after unmatched high-quality spectra are prioritized. This focused use preserves efficiency while still recovering sequence evidence that would otherwise be lost.
Which Approach Fits Different Study Goals
The best choice depends on what the study must prove.
Choose reference-based search when the sample comes from a well-annotated proteome, the goal is broad protein identification or quantification, and the expected sequences are already represented in the reference database. Typical examples include cell-line proteomics, pathway analysis, biomarker screening in human samples, and many discovery experiments on model organisms.
Choose sequence-from-spectrum analysis when the protein sequence is unknown, proprietary, engineered, or likely to differ from available references. Typical examples include unknown protein bands, antibody sequencing, novel venom or microbial proteins, variant-containing peptides, and sequence confirmation for recombinant products.
Choose a hybrid workflow when most peptides in the sample can be identified by reference matching, but a subset of high-value spectra require sequence derivation. This is common in antibody projects, biosimilar assessment, metaproteomics, and biopharmaceutical comparability studies.
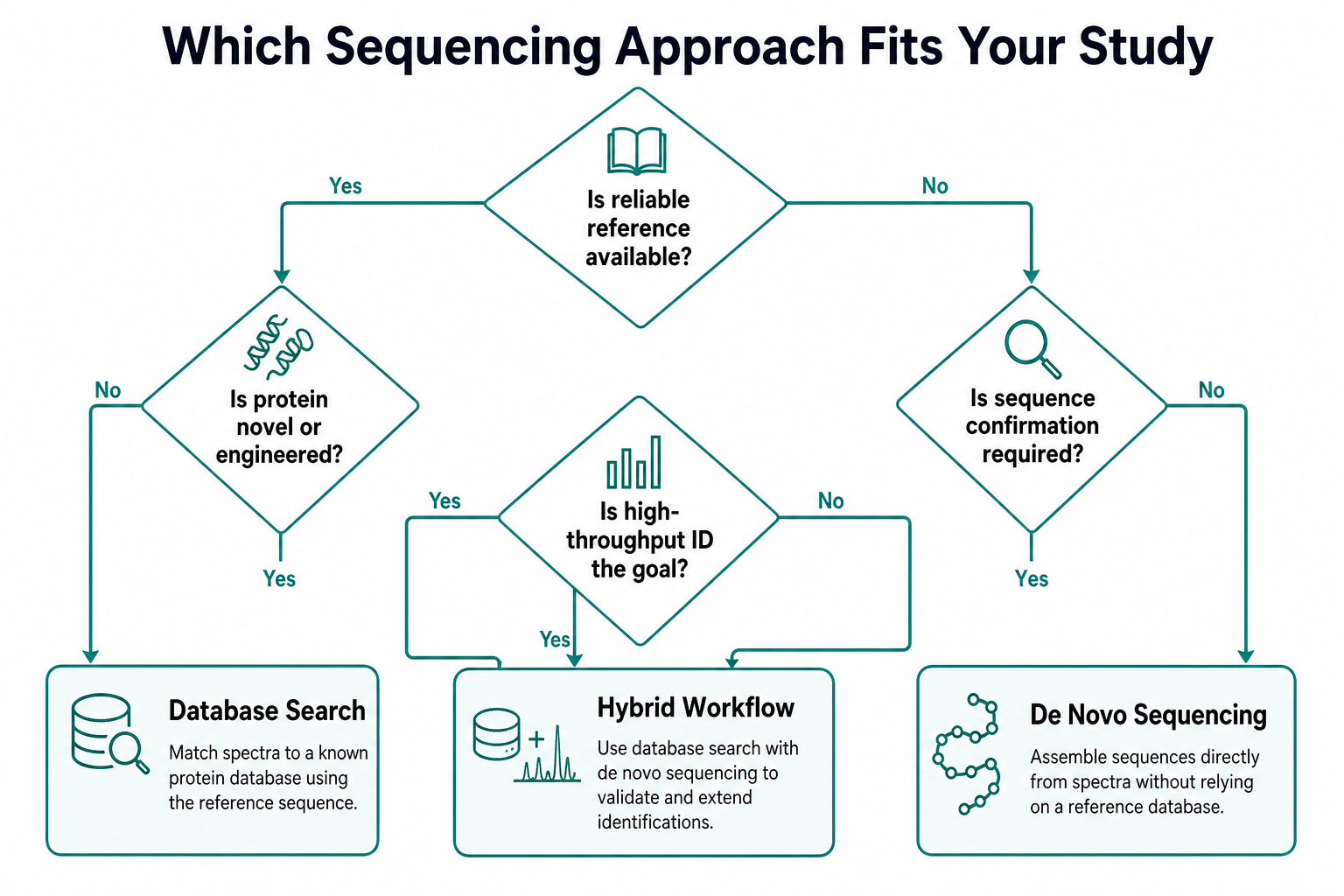
Figure 2. Decision flow for choosing the right sequencing approach
Researchers should also consider reporting depth. If the project only needs protein names and relative abundance, reference-based search may be enough. If the project needs residue-level confirmation, overlap coverage, or documentation for cloning and regulatory review, the de novo route or confirmatory MS should be planned from the start.
Hybrid Workflows Often Provide the Best Balance
A strict either-or choice is not always necessary. A practical hybrid workflow may include reference matching for the majority of peptides, followed by de novo analysis of unmatched spectra, low-scoring matches, or regions with prior biological evidence of sequence divergence. This approach is often more cost-effective than performing sequence-from-spectrum analysis on every spectrum in a complex lysate.
Hybrid strategies are especially useful when:
The hybrid model preserves throughput while still creating a path to novel sequence recovery.
Limitations to Keep in Mind
Neither method is universally superior. Reference-based search is only as good as the reference database and search parameters. Incomplete databases, poor enzyme specificity settings, and underestimated modification complexity can all reduce identification quality. The de novo route depends on spectrum quality and expert review. Ambiguous residues, chimeric spectra, and isoleucine or leucine uncertainty can limit confidence.
Researchers should also avoid switching methods without changing expectations. Reference matching is optimized for identification coverage. Sequence-from-spectrum analysis is optimized for sequence derivation. Comparing the two only by number of identified peptides can lead to the wrong conclusion when the real need is sequence confirmation.
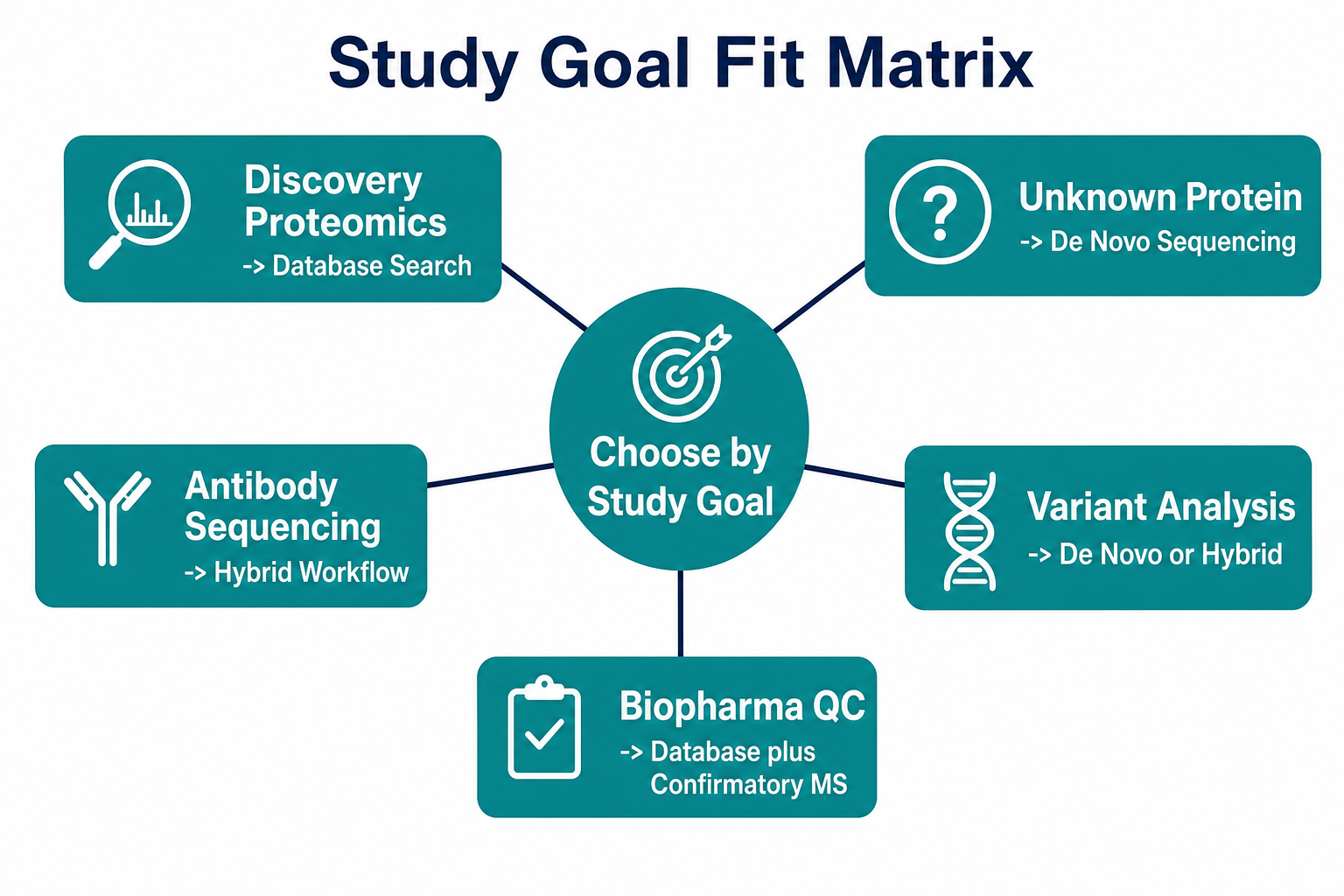
Figure 3. Matching sequencing approach to study goal
Practical Selection Checklist
Before starting data analysis, answer these questions:
If reference coverage is strong and the goal is broad discovery, reference-based search is usually sufficient. If reference coverage is uncertain and the goal is sequence proof, the de novo route or a hybrid workflow is usually the better fit.
Frequently Asked Questions
1. Is de novo sequencing better than database search?
Neither method is better in all cases. Database search is better for high-throughput identification when references are reliable. The de novo route is better when the sequence may be absent, incorrect, or intentionally modified.
2. Can I use database search for unknown proteins?
Reference-based search can identify homologs if related sequences exist in the database. If the protein is truly novel or too divergent, sequence-from-spectrum analysis is usually needed to derive the peptide sequence directly.
3. When should a project use both methods?
A hybrid workflow is useful when most peptides can be identified by reference matching but a subset of unmatched or biologically important spectra require de novo interpretation.
4. Which method is faster?
Reference-based search is generally faster and more scalable for large datasets. The de novo route requires more manual interpretation and is usually applied to selected spectra or enriched samples.
5. Which approach is better for antibody sequencing?
Antibody sequencing often requires a hybrid or de novo-focused workflow because variable- region sequences may be incomplete in reference files and may require MS-derived peptide assembly.
Conclusion
Reference matching and de novo sequencing serve different proteomics needs. Reference-based search fits discovery studies with strong reference coverage and high-throughput protein identification goals. Sequence-from-spectrum analysis fits projects that require sequence derivation for unknown, engineered, or variant-containing proteins. Hybrid workflows often provide the best balance when only a subset of spectra needs sequence-level interpretation.
If your study sits at the boundary between identification and sequence proof, contact MtoZ Biolabs to discuss whether reference matching, sequence-from-spectrum analysis, unknown protein analysis, or a combined MS workflow is the right fit for the project.
How to order?

