





Applications of PhIP-Seq in Genomics
-
Selecting a genome-derived or custom peptide library.
-
Incubating serum, plasma, or another antibody-containing sample with the library.
-
Capturing antibody-bound phage particles.
-
Sequencing enriched peptide-encoding DNA.
-
Mapping reads back to peptide and antigen annotations.
-
Comparing enrichment across groups, phenotypes, or time points.
-
Prioritizing candidates for validation.
-
Broad screening across pathogen proteomes.
-
Comparison of exposed and unexposed groups.
-
Mapping of immunodominant peptide regions.
-
Evaluation of response breadth after vaccination.
-
Discovery of cross-reactive peptide motifs.
-
Peptide enrichment scores mapped to gene or antigen annotations.
-
Coverage tracks across selected proteins or pathogen regions.
-
Reference-versus-variant peptide comparisons.
-
Cohort-level heatmaps and clustering summaries.
-
Candidate antigen tables with validation recommendations.
-
Notes on library coverage, missing regions, and assay limitations.
-
Library coverage — genomic regions absent from the library cannot be detected.
-
Annotation quality — incorrect gene models or isoform choices can affect mapping.
-
Cross-reactivity — similar peptide motifs can appear across related proteins or pathogens.
-
Background binding — some peptide clones may enrich in controls.
-
Linear epitope bias — conformational or modification-dependent epitopes may be missed.
-
Validation burden — broad screens can produce more candidates than a team can test.
Introduction
Genomics has made it easier to predict thousands of protein-coding regions, variants, pathogen proteins, and disease-associated antigen candidates. The harder question is which encoded regions are actually recognized by antibodies in biological samples. A genome can identify possible antigens, but a genome alone does not show which peptide regions are immunoreactive in serum, plasma, or disease cohorts. Researchers often need a bridge between sequence information and functional antibody recognition.
PhIP-Seq, also called phage immunoprecipitation sequencing, can provide that bridge. The method uses DNA-encoded phage display peptide libraries to represent genomic, proteomic, pathogen-derived, or custom antigen spaces. Antibody-containing samples enrich the displayed peptides that antibodies recognize. Sequencing then identifies the peptide-encoding sequences. In genomics-oriented studies, the value comes from connecting sequence-defined libraries with antibody reactivity patterns.
For teams working on immune genomics, infection serology, autoantigen discovery, or tumor antigen screening, MtoZ Biolabs can help evaluate whether a PhIP-Seq library design and analysis plan fit the biological question, sample type, and validation goal.
Related Services
| Research Need | Recommended Service |
| Broad antibody profiling against sequence-defined peptide libraries | PhIP-Seq Antibody Analysis Service |
| Peptide-level epitope interpretation after screening | Antibody Epitope Mapping Service |
| Targeted validation of candidate peptide regions | Peptide Array-Based Epitope Mapping Service |
| Antibody sequence support for follow-up discovery programs | Antibody Sequencing Service |

Figure 1. PhIP-Seq connects sequence-defined peptide libraries with antibody reactivity profiles.
How PhIP-Seq Connects Genomic Information to Antibody Recognition
The genomic connection begins with library design. Protein-coding sequences, pathogen genomes, variant regions, open reading frames, or custom antigen panels can be translated into peptide designs. These peptide designs are displayed on phage particles, and each peptide is linked to a DNA sequence that can be counted by sequencing.
The assay does not sequence the genome of the sample donor. The assay uses sequencing as a readout to identify which library peptides were enriched after antibody capture. This distinction matters. PhIP-Seq is best understood as an antibody profiling method built on sequence-defined libraries and sequencing-based quantification.
The workflow usually includes:
Genomics-Oriented Library Designs
The library determines which genomic or proteomic regions can be tested. A poor library match can create false negatives because antibodies cannot enrich peptides that are absent, underrepresented, or poorly displayed.
| Library Type | Genomics-Oriented Use | Typical Output | Key Limitation |
| Human proteome- derived library | Autoantibody discovery and immune-genomics studies | Candidate self- antigens or reactive regions | Background reactivity can be high |
| Pathogen genome- derived library | Infection history and exposure profiling | Pathogen peptide signatures | Cross-reactivity may require validation |
| Variant- focused library | Immune recognition of mutations or strain differences | Variant-associated peptide candidates | Requires accurate variant selection |
| Tumor antigen library | Cancer immune-response screening | Candidate tumor- associated regions | Native structure may not be represented |
| Custom gene panel library | Hypothesis-driven antigen screening | Focused candidate list | Depends on prior biological assumptions |
Library design should consider peptide length, tiling overlap, coding sequence annotation, isoform selection, variant placement, redundancy, and expected epitope type. Linear peptide libraries are useful for sequence-localized recognition. Structure-dependent epitopes, glycan- dependent recognition, and native protein-complex epitopes usually require additional methods.
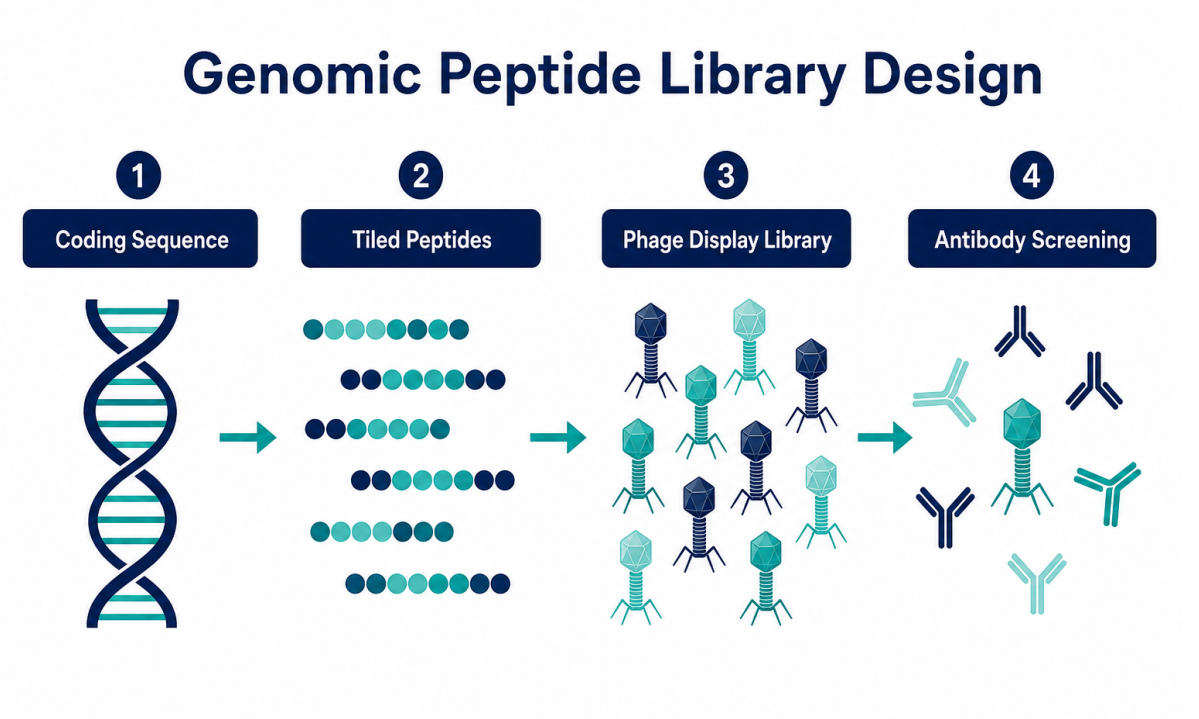
Figure 2. Genomics-oriented libraries translate sequence information into peptide panels for antibody screening.
Application 1: Autoantigen Discovery from Proteome-Derived Libraries
Autoimmune disease research often involves heterogeneous antibody responses. A targeted assay may detect known autoantibodies, but targeted testing can miss uncharacterized antigen regions. A human proteome-derived peptide library can help screen broad self-peptide space and identify candidate autoantigens.
In this setting, the key question is not simply whether a peptide is enriched. The stronger question is whether enrichment is associated with a disease group, disease subtype, severity score, treatment response, or longitudinal change. Controls should be chosen carefully because healthy individuals may also show background reactivity to some self-peptides.
Useful outputs include disease-associated peptide regions, antigen-level summaries, heatmaps across cohorts, and validation shortlists. Candidate regions should be tested with orthogonal assays before being treated as mechanistic evidence.
Application 2: Pathogen Genomics and Serological Exposure Profiling
Pathogen genomes can be translated into peptide libraries that represent viral, bacterial, fungal, or parasitic proteins. These libraries can help researchers profile antibody responses to infection exposure, vaccination, reinfection, or disease progression.
For infectious disease studies, PhIP-Seq in genomics can support:
Interpretation should consider prior exposure, vaccination status, geography, sampling time, and cross-reactivity. A peptide enriched in exposed samples may reflect current infection, past exposure, vaccination, or shared motifs across related organisms.
Application 3: Variant and Strain-Specific Immune Recognition
Genomic variation can change peptide sequences. In pathogen research, strain-specific mutations may alter antibody recognition. In cancer research, mutation-derived peptides may create new candidate antigen regions. In population studies, sequence diversity can also affect antigen representation.
Variant-focused libraries can compare reference and variant peptide sequences in the same screening design. This approach can help identify whether antibody reactivity is shared across variants or enriched toward specific sequence changes.
| Variant Question | Library Strategy | Interpretation Need |
| Does a mutation change antibody binding? | Pair reference and variant peptides | Compare matched peptide enrichment |
| Are strain-specific regions immunoreactive? | Tile strain-specific proteins | Control for shared motifs |
| Are candidate tumor variants recognized? | Include mutation- containing peptides | Validate with tumor- relevant assays |
| Does immune recognition differ by cohort? | Screen variants across groups | Account for exposure and metadata |
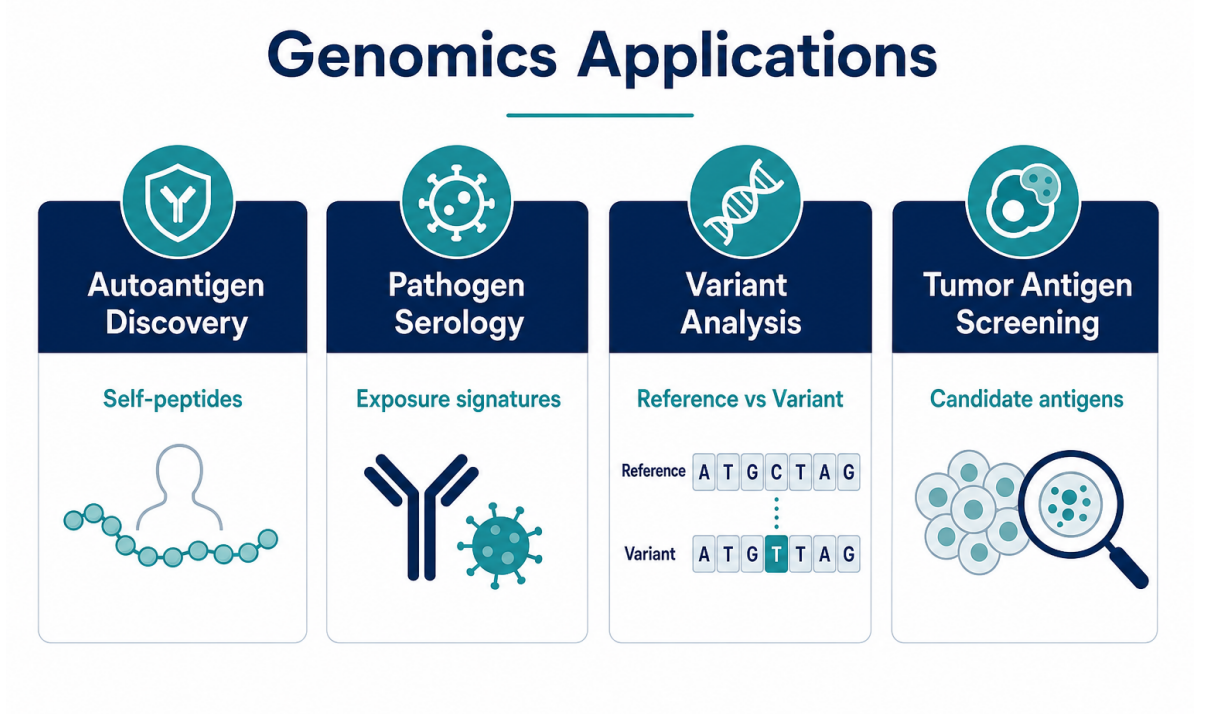
Figure 3. Genomics-oriented applications include autoantigen discovery, pathogen exposure profiling, variant analysis, and tumor antigen screening.
Application 4: Tumor Antigen and Cancer Immune- Response Studies
Cancer genomics can identify tumor-associated genes, mutations, and expression patterns. PhIP- Seq can complement these data by screening whether patient antibodies recognize peptide regions derived from selected tumor antigens or custom panels.
The assay is most useful when the research question involves linear peptide recognition or exploratory antibody profiling. The assay is less direct when the candidate antigen depends on native protein folding, post-translational modification, glycosylation, or protein complexes.
For cancer immune-response studies, candidate peptide signals should be interpreted with tumor type, treatment status, sample timing, and control groups. Follow-up may include peptide arrays, ELISA, protein-based binding assays, or tumor-specific validation cohorts.
Integrating PhIP-Seq with Other Genomics Data
PhIP-Seq results become more informative when antibody reactivity is connected with other genomic or molecular data. Integration can help prioritize candidates that are not only enriched by antibodies but also biologically plausible.
| Data Type | Integration Value | Example Use |
| Genome annotation | Links peptides to genes, proteins, and regions | Identify antigen source and function |
| Variant data | Adds mutation or strain context | Compare reference and variant reactivity |
| Transcriptomics | Shows whether antigen genes are expressed | Prioritize candidates with expression support |
| Proteomics | Confirms protein-level evidence | Connect antibody targets to detected proteins |
| Clinical metadata | Links antibody patterns to phenotype | Support subgroup or outcome analysis |
Integration should not replace validation. Integrated evidence can rank candidates, but antibody- reactive peptides still need confirmation in independent assays or cohorts.
Data Outputs from Genomics-Oriented PhIP-Seq
Genomics-oriented studies should produce outputs that preserve both sequence context and antibody enrichment. A ranked peptide list is useful, but a list without genomic annotation can be hard to interpret.
Typical outputs include:
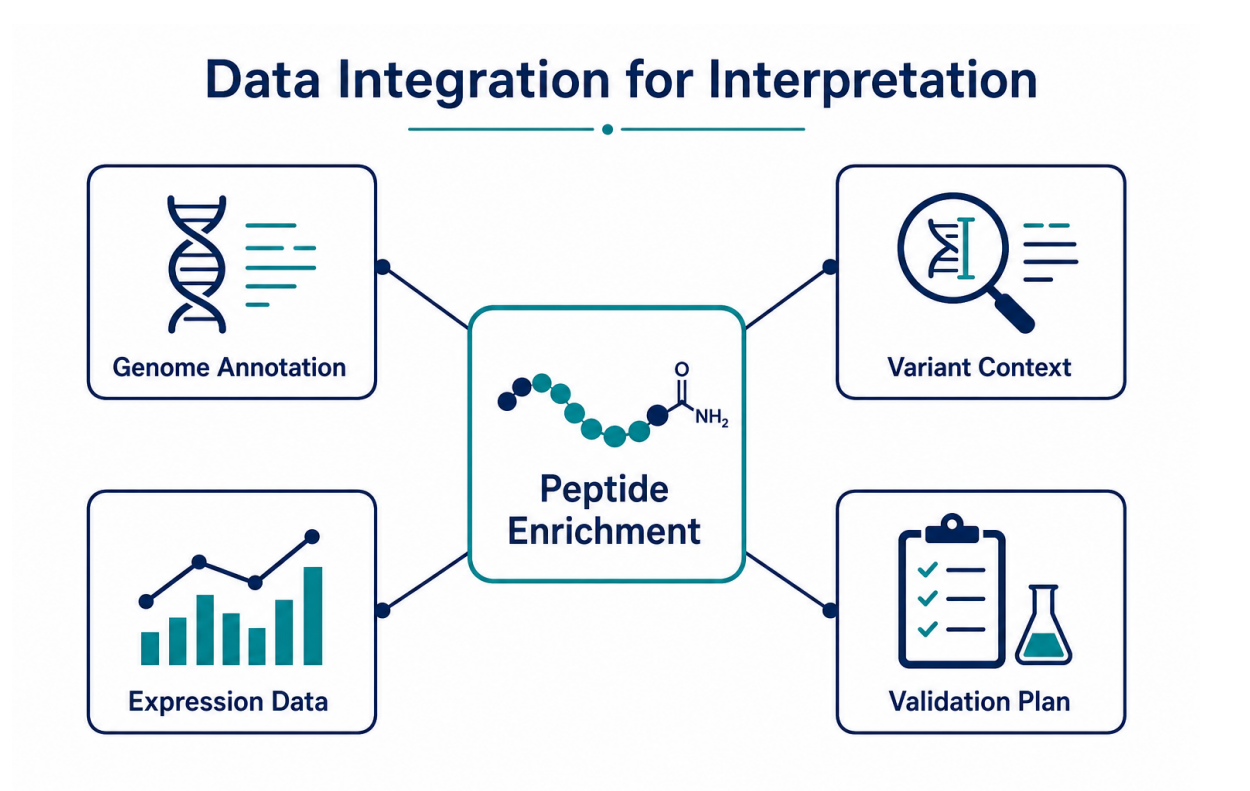
Figure 4. Genomics-oriented interpretation links peptide enrichment with annotation, variant context, expression evidence, and validation planning.
Challenges in Genomics Applications
PhIP-Seq can add functional immune context to sequence-defined libraries, but several challenges should be addressed before interpretation.
These issues can be managed through careful library design, input sequencing, negative controls, replicate checks, metadata-aware analysis, and a focused validation plan.
Frequently Asked Questions
1. Is PhIP-Seq a genomics method?
PhIP-Seq is not a method for sequencing a sample genome. The assay uses sequencing to read out antibody enrichment against DNA-encoded peptide libraries. The genomics connection comes from sequence-defined library design and annotation.
2. How does PhIP-Seq support immune genomics?
The method links antibody reactivity to peptide regions derived from genes, proteomes, pathogen genomes, variants, or custom antigen panels. This helps researchers connect immune recognition with sequence-defined antigen space.
3. Can PhIP-Seq analyze pathogen genomes?
Yes. Pathogen coding sequences can be translated into peptide libraries for serological profiling, exposure studies, vaccine response analysis, or cross-reactivity research.
4. Can variant peptides be compared in the same experiment?
Yes, if the library includes both reference and variant peptides. Interpretation should compare matched peptides and account for background, cross-reactivity, and sample metadata.
5. What validation is needed after genomics-oriented screening?
Candidate peptides may be validated with peptide arrays, ELISA, targeted immunoassays, Western blotting, or protein-based binding assays. The validation method should match the antigen type and research goal.
Conclusion
PhIP-Seq in genomics is most useful when researchers need to connect sequence-defined antigen libraries with functional antibody recognition. The method can support autoantigen discovery, pathogen serology, variant analysis, tumor antigen screening, and integrated immune-genomics studies. Strong results depend on library design, controls, metadata, annotation quality, and validation planning.
For teams using genomic information to design peptide libraries or interpret antibody reactivity, the next step is to align the library scope with the biological question. Contact MtoZ Biolabs to discuss whether PhIP-Seq in genomics is suitable for the sample set, sequence targets, and validation strategy of the project.
How to order?

