





PhIP-Seq Applications in Autoantibody and Antigen Discovery: When the Method Fits the Research Question
- survey broad antigen space rather than test a short predefined panel,
- compare seroreactivity across cases, controls, or subgroups,
- nominate candidate antigen regions for follow-up,
- and refine hypotheses before moving into orthogonal validation.
- Use peptide-based confirmation when the goal is to verify a linear epitope or compare nearby sequences.
- Use protein-level assays when the key question is whether the candidate antigen stays reactive in a fuller structural context.
- Use cell-based or native-context assays when membrane presentation or conformational epitope recognition sits at the center of the biology.
- Use targeted cohort assays when the project needs a narrower validation panel after broad discovery.
PhIP-Seq is often a strong discovery method when the real goal is broad peptide-space screening, linear epitope mapping, and cohort-level comparison of seroreactivity patterns. It is a weaker first choice when the main question depends on intact protein recognition, conformational epitope readout, calibrated quantitation of a known target, or evidence that is ready for confirmation right away.
The reason is simple. PhIP-Seq combines a phage-displayed peptide library, antibody immunoprecipitation, and next-generation sequencing to measure peptide enrichment. That makes it useful for discovery-stage autoantibody profiling and antigen discovery at scale, but it does not directly show how antibodies interact with a fully native antigen. So the practical question is not whether PhIP-Seq is powerful in the abstract. It is whether the assay matches the biology, cohort design, and validation plan in front of you.
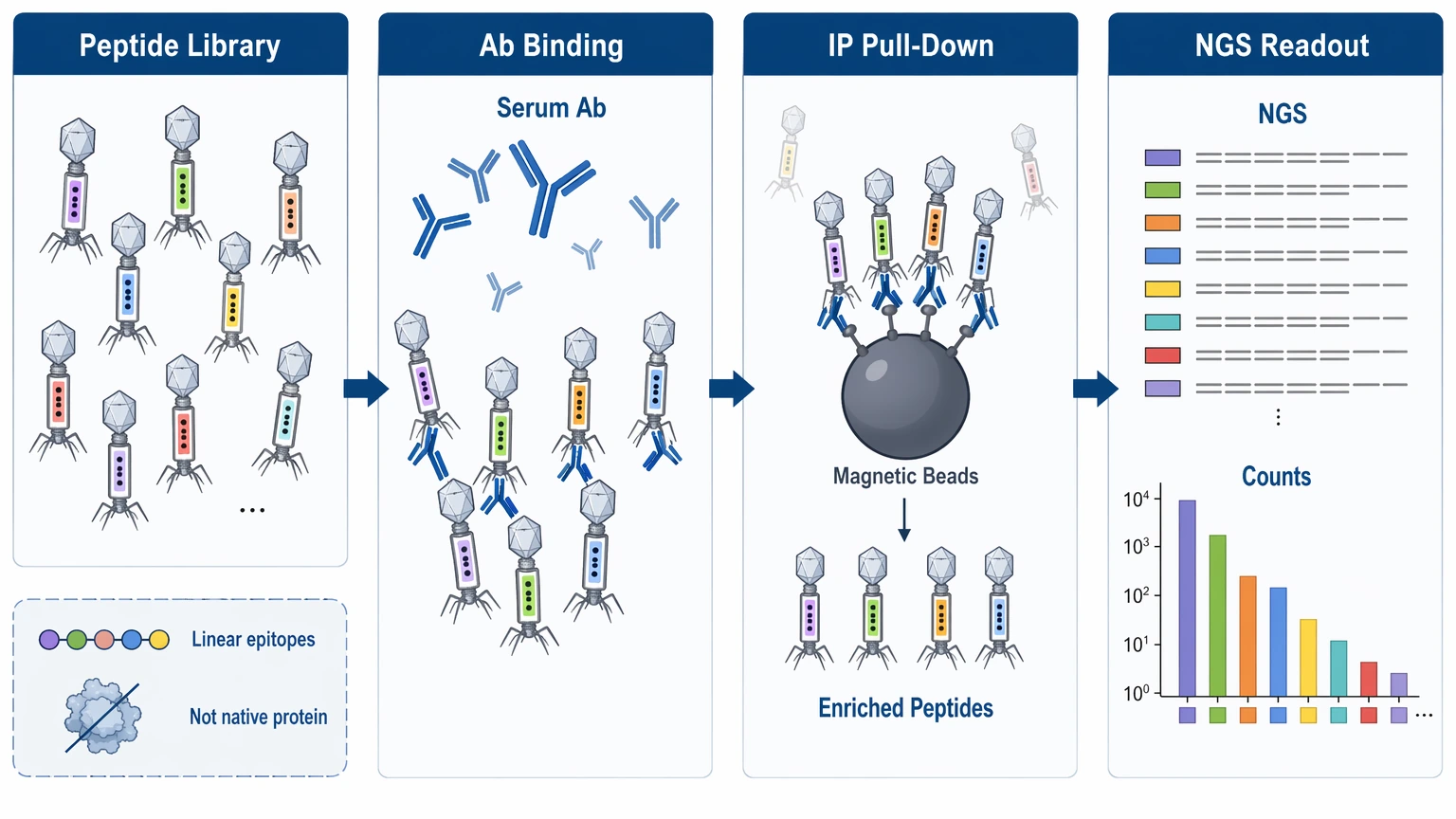
What PhIP-Seq Actually Reads Out
PhIP-Seq reports which peptides become enriched after antibodies in serum or plasma pull them down from a phage-displayed peptide library. Researchers usually interpret the output through read count changes, normalized counts, and enrichment analysis across samples or study groups.
That distinction matters. The signal is relative and sequence-based. A peptide-level result can point to a candidate antigen, an epitope-rich region, or a recurring disease-associated pattern across a cohort. On its own, though, it does not establish protein-level relevance, functional significance, or clinical interpretability.
In practice, PhIP-Seq tends to work best when researchers want to:
Research Questions That Fit PhIP-Seq Well
PhIP-Seq usually makes sense as the lead method when discovery breadth matters more than immediate confirmation. Four use cases come up again and again.
Broad peptide-space screening across cohorts
If a team has patient and control samples and wants to search across large sequence space, PhIP-Seq can uncover recurring peptide enrichment patterns that narrower assays would never look for. That is especially helpful in exploratory autoimmune studies where the relevant antigens are still uncertain.
Linear epitope and region-level mapping
The method fits projects centered on linear epitope discovery or dense sequence tiling. When several enriched peptides overlap within the same antigen region and recur in related samples, those candidates are easier to rank for follow-up.
Subgroup comparison in heterogeneous disease
Some studies are not chasing one target. They are asking whether different disease subsets show different seroreactivity signatures. PhIP-Seq can support that kind of cohort-level comparison when cases, controls, and subgroup labels are defined clearly enough for meaningful enrichment analysis.
Early-stage target nomination
For translational teams deciding which candidates deserve more work, PhIP-Seq can act as a first filter. It narrows a large search space to a shorter list of candidate antigens, as long as orthogonal validation is built into the plan from the beginning.
When Another Assay Should Lead
PhIP-Seq is not the right first move for every antibody discovery question. Its main limits come from antigen presentation and the kind of readout it produces.
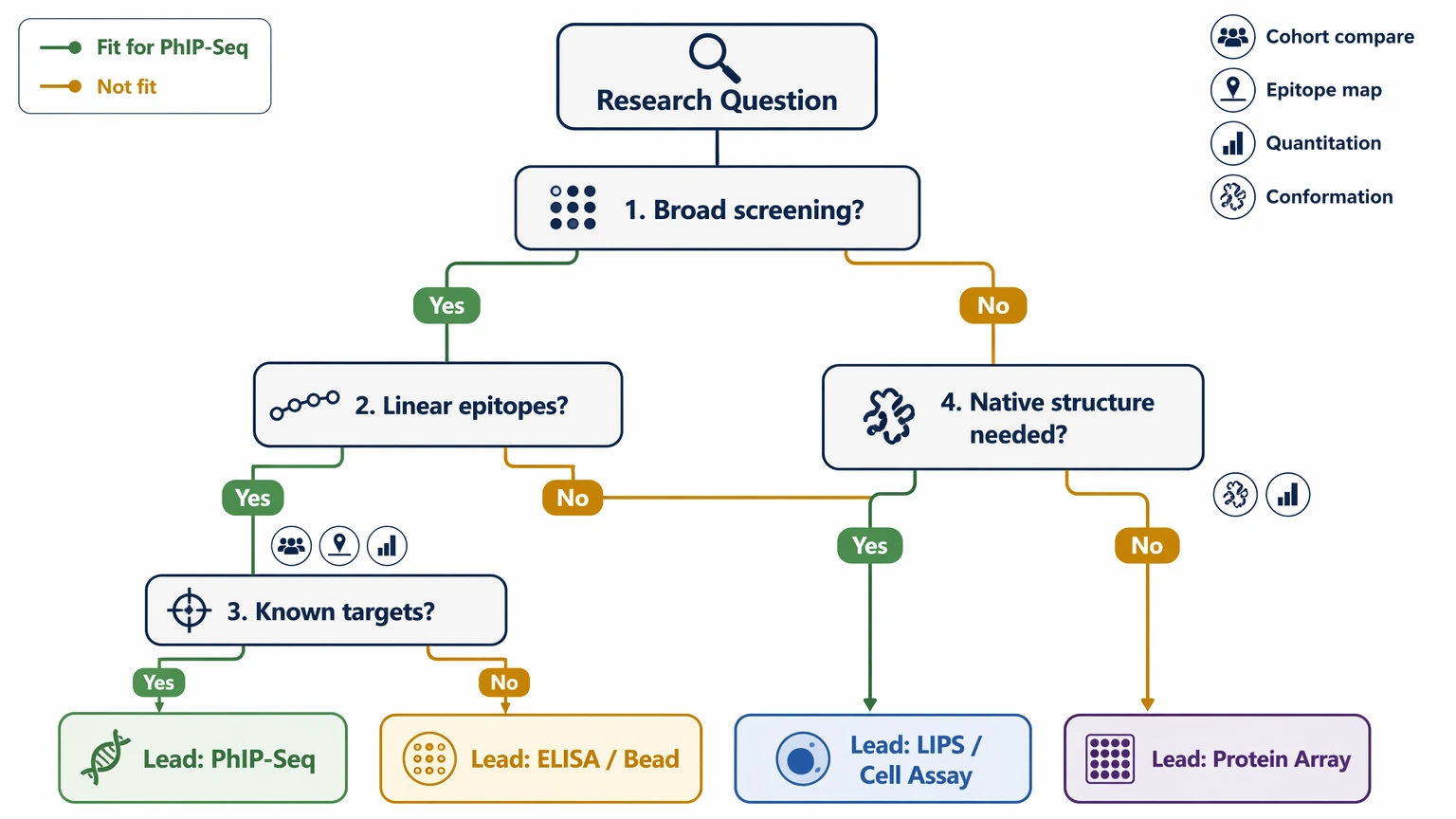
When conformational epitope recognition is likely
If the biology points to conformational epitope binding, native folding, multimeric assembly, membrane presentation, glycosylation, or other post-translational modifications, peptide display may miss the dominant interaction. In that situation, protein array, LIPS, or cell-based assay formats usually make more sense as the primary readout.
When the target list is already narrow
If the team mainly needs to compare known antigens across a cohort, a targeted assay such as ELISA or a bead-based immunoassay is often the more direct option. These methods are usually easier to interpret for predefined targets and often line up better with later validation goals.
When the project needs calibrated quantitation
PhIP-Seq is enrichment-based, not a calibrated antigen-specific concentration assay. If the study decision depends on quantitative comparison of a small number of known antibodies, another platform should usually lead.
When follow-up capacity is limited
A broad discovery screen creates a validation burden. If the study cannot support orthogonal confirmation, the practical value of a long hit list drops fast.
Related Services
Main Service
Supporting Service
Validation Service
Alternative Service
How PhIP-Seq Compares With Other Antibody Profiling Approaches
| Dimension | PhIP-Seq | ELISA / bead-based assay | Protein array / intact-antigen screen | LIPS / cell-based assay |
|---|---|---|---|---|
| Primary readout | Peptide enrichment from normalized counts after immunoprecipitation and next-generation sequencing | Target-specific signal against predefined antigens | Binding to immobilized proteins or domains | Binding in a more native antigen context |
| Best research fit | Broad autoantibody profiling, antigen discovery, epitope mapping, cohort-level comparison | Known-target confirmation or relative comparison | Wider antigen screening with more protein context | Native-antigen follow-up and conformational epitope evaluation |
| Main strength | Large sequence coverage and flexible tiling | Focused interpretation for selected targets | Better protein-level context than peptide-only display | Better alignment with structure-dependent binding |
| Main limitation | Reduced representation of conformational epitopes and some modifications | Limited discovery breadth | Content is restricted to arrayed proteins and their quality | Narrower discovery breadth than peptide-library screening |
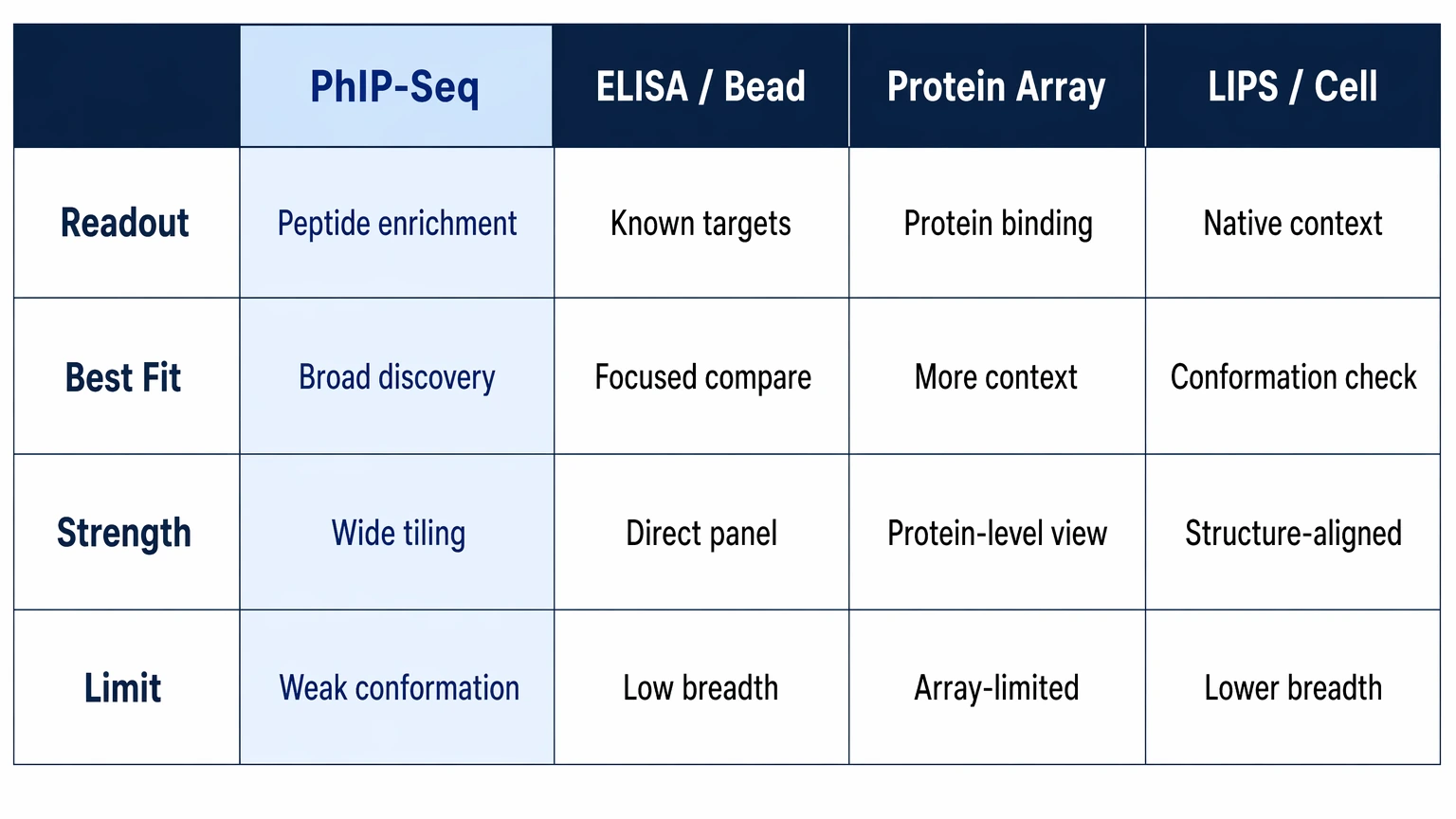
The useful comparison is not which method wins in general. It is where each method belongs in the study sequence. PhIP-Seq often sits upstream as the discovery engine. Intact-antigen and targeted assays usually matter more once the project moves into confirmation.
If your team is deciding between peptide-library screening and intact-antigen follow-up, this is the point to evaluate your project against likely epitope type, cohort structure, and downstream assay needs. For studies involving library planning, immunoprecipitation-sequencing workflow design, and hit prioritization, MtoZ Biolabs can review the proposed sample set and help match the screen design to a workable validation path.
How to Interpret Peptide Enrichment Without Overcalling the Result
The most common mistake is treating a peptide hit as direct proof of a disease-relevant native antigen. A better reading starts with four questions.
First, is the peptide-level signal recurrent across the relevant disease group, or does it appear in only one or two samples? Recurrent enrichment usually carries more weight than isolated hits.
Second, do multiple enriched peptides map to the same antigen region? Overlap among enriched peptides can strengthen epitope mapping and candidate antigen nomination.
Third, how does the signal behave against background reactivity in controls? A peptide that appears broadly across controls may reflect nonspecific binding or common seroreactivity rather than disease association.
Fourth, is the inferred antigen biologically plausible in the disease context? Sequence-level mapping still needs to be filtered through tissue relevance, antigen class, and consistency with the study hypothesis.
None of these checks removes uncertainty. They do make it easier to separate a peptide-level signal from a candidate antigen that is worth pursuing.
Study Design Features That Make a PhIP-Seq Project More Interpretable
A well-matched assay can still produce weak conclusions if the study design is thin. For PhIP-Seq, the decisions that matter most usually fall into four categories: library design, cohort structure, sequencing readout quality, and validation planning.
1. Library design
The phage-displayed peptide library should reflect the actual hypothesis space. Sequence coverage, peptide length, and tiling density directly shape what can be found. Human proteome tiling, viral content, microbial antigens, or custom candidate sets should be chosen because they fit the disease question, not because they make the library look broader.
2. Cohort structure
Interpretation gets cleaner when cases and controls are balanced, subgroup labels are consistent, and batch allocation is planned before screening starts. Reference sera, technical replicates, and negative controls can help separate disease-associated seroreactivity from baseline background.
3. Sequencing and enrichment behavior
Teams should look closely at read count distribution before and after immunoprecipitation, normalized counts across samples, sequencing depth per sample, and the stability of enrichment analysis across batches. Those metrics shape how confidently weak signals can be ranked.
4. Hit prioritization and orthogonal validation
Before screening begins, define how hits will move forward. Useful filters include recurrence, effect size versus controls, overlap within an antigen region, and whether confirmation is feasible by ELISA, LIPS, Western blot, bead-based assay, peptide array, or cell-based assay.
What Validation Should Follow a Promising PhIP-Seq Result
The follow-up assay should answer the uncertainty left by the discovery result.
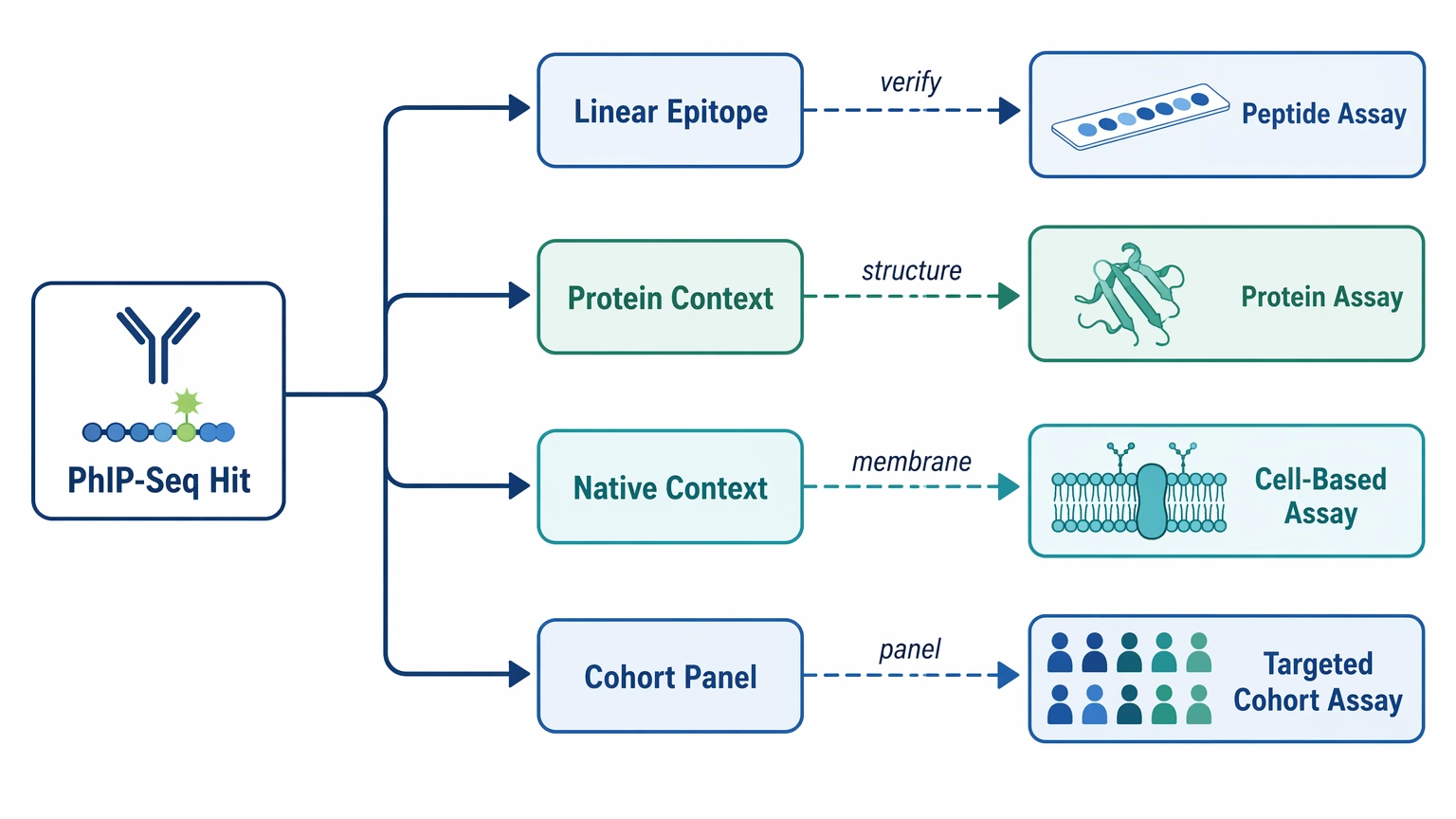
This staged approach usually leads to cleaner decisions than expecting one platform to do everything. PhIP-Seq can nominate. Orthogonal validation decides which candidates actually hold up.
Comparison Summary and Next-Step Guidance
PhIP-Seq is most useful when a project needs broad peptide-space interrogation, peptide-level signal ranking, and cohort-scale autoantibody profiling. It is less suitable as a stand-alone method when the biology depends on conformational epitopes, intact protein context, or target-specific quantitative readout. For serum or plasma discovery programs, the best fit usually comes from aligning library scope, cohort design, enrichment analysis, and the validation route before launch. If your team is preparing a PhIP-Seq study or comparing it with intact-antigen follow-up methods, submit your requirements or contact us at MtoZ Biolabs to discuss the planned sample set, expected readout, and confirmation workflow.
FAQ
How large does a cohort need to be for PhIP-Seq to be informative?
There is no single cutoff, but very small cohorts make it harder to separate recurrent disease-associated seroreactivity from background reactivity. The more heterogeneous the disease, the more important matched controls and clear subgroup definitions become.
Can PhIP-Seq be used with custom antigen space rather than a broad proteome library?
Yes. Custom libraries can be useful when prior biology already narrows the search space to certain pathogens, tissue-restricted proteins, or candidate pathways. The tradeoff is straightforward: tighter scope improves focus but lowers the chance of finding unexpected off-target or off-panel signals.
What is a realistic “hit” after PhIP-Seq screening?
A realistic hit is usually a prioritized peptide-level signal or candidate antigen region supported by recurrence, separation from controls, and plausible mapping to the study question. It is not the same thing as a validated biomarker.
How should teams handle low-frequency enriched peptides?
Treat them cautiously. Rare signals may still matter, but they usually need stronger supporting evidence, such as overlapping peptides, consistency across technical replicates, or confirmation in an independent assay.
Is PhIP-Seq useful after another assay has already found candidate targets?
Yes. It can serve as a complementary layer when researchers want finer epitope mapping, broader comparison around a suspected antigen family, or a cohort-level view of peptide-region recurrence.
What should be ready before requesting a feasibility review?
Prepare the sample type, sample count, disease and control groups, suspected linear versus conformational epitope biology, preferred library scope, and the kind of orthogonal validation the study can support after discovery.
How to order?

