





De Novo Sequencing When Database Search Fails: A Practical Troubleshooting Guide
-
the search engine reports low-scoring peptide matches
-
only a few peptides are identified, despite visible protein signal
-
multiple unrelated proteins are returned from a supposedly pure sample
-
the matched sequence clearly does not fit the expected molecular weight or biology
-
the protein comes from a species or construct not represented in the selected database
-
the project involves a proprietary or engineered sequence not present in public repositories
-
assembled sequence regions with confidence annotations
-
peptide coverage map showing supported and unsupported segments
-
annotated MS/MS spectra for major sequence calls
-
notes on ambiguous residues or low-confidence areas
-
recommendations for follow-up validation if full coverage was not achieved
-
Intact mass measurement to confirm overall molecular weight consistency
-
N-terminal or C-terminal sequencing for boundary confirmation
-
Peptide mapping when a reference becomes available after initial de novo recovery
-
Recombinant expression and functional testing when the sequence will be used for production
-
Do not assume that a failed database search always means database-free sequencing is required. Sometimes the issue is sample quality, incorrect database selection, or a simple contamination problem.
-
Do not treat partial coverage as full sequence confirmation. Low-coverage regions should be reported with appropriate caution.
-
Do not skip metadata. Accurate sample history helps the sequencing team choose digestion strategy, interpret homologous regions, and avoid unnecessary repeat analysis.
Introduction
A failed database search is one of the most frustrating outcomes in a protein characterization project. The sample may be pure enough to detect clearly by SDS-PAGE or LC-MS, yet the search engine returns weak matches, low coverage, or multiple unrelated protein candidates. For a lab preparing a manuscript, validating a recombinant product, or documenting a proprietary protein, this result creates immediate uncertainty.
Database-assisted protein identification works well when the correct reference sequence is present and the experimental data are strong. It becomes unreliable when the protein is novel, the database is incomplete, the sample is degraded, or the search parameters do not fit the actual sample history. In these cases, repeating the same database search rarely solves the problem.
Database-free sequencing offers a practical next step because it does not depend on finding a pre-existing match. Instead, the workflow interprets MS/MS fragment ions directly and rebuilds sequence information from overlapping peptide evidence. If your team is stuck after a failed database search, MtoZ Biolabs can assess sample readiness and recommend whether de novo sequencing, terminal analysis, or peptide mapping is the most efficient recovery route.
Common Pain Points After a Failed Database Search
Researchers usually contact a sequencing provider after one or more of the following problems:
These outcomes are common in recombinant protein QC, antibody-related work, environmental or microbial samples, and legacy material with incomplete records. The issue is often not instrument failure. It is a mismatch between the available reference information and the actual sample.
Why Database Search Fails
Before switching methods, it helps to understand why database-assisted identification breaks down. The most common causes fall into three groups.
1. Missing or Incorrect Reference Information
If the true sequence is absent from the selected database, no search algorithm can recover it reliably. This happens with novel proteins, proprietary constructs, unannotated organisms, and incomplete internal sequence records.
2. Spectral Quality Limitations
Weak fragmentation, low signal-to-noise ratios, co-eluting peptides, and instrument tuning issues can all reduce the number of usable spectra. Even a correct reference cannot be matched confidently from poor-quality data.
3. Sample and Preparation Issues
Protein degradation, mixed samples, insufficient amount, incompatible buffer components, and suboptimal digestion strategy can all reduce peptide coverage and search confidence.

Figure 1. Failed database search often reflects missing references, spectral quality issues, or sample preparation problems.
Related Services
| Customer Need | Recommended Service Direction |
|---|---|
| Want to confirm purified protein identity | |
| Want to confirm if the N-terminal or C-terminal is correct | / |
| Want to verify recombinant protein sequence coverage | |
| No reliable database sequence | |
| Want to analyze truncation, modification, or processing events |
Step-by-Step Recovery Guide
When database search fails, use a structured review rather than repeating the same analysis with minor parameter changes.
Step 1: Confirm Sample Quality
Check whether the sample is truly the intended protein and whether it is sufficiently pure for sequencing. Review SDS-PAGE, intact mass data if available, and sample handling history. Degraded, mixed, or insufficient samples often fail before sequence interpretation begins.
Step 2: Review Search Settings
Confirm that the correct database, taxonomy, enzyme specificity, missed cleavage allowance, and mass tolerances were used. A wrong species database or overly strict search settings can eliminate valid matches. Still, if the correct sequence is genuinely absent, better parameters alone will not create a reliable reference.
Step 3: Evaluate Spectral Coverage
Determine whether the issue is poor data quality or missing reference information. If only a few peptides are observed, additional digestion, fractionation, or repeat LC-MS/MS may help. If the spectra are strong but no credible match appears, database-free sequencing is often the better next step.
Step 4: Switch to Database-Free Sequencing When No Reference Exists
The method interprets peptide fragment patterns directly and assembles sequence tags into longer regions. This approach is especially useful for unknown proteins, proprietary sequences, and recombinant products that do not match public database entries.
Step 5: Plan Validation Before Final Reporting
Recovered sequence regions should be checked against intact mass, terminal sequencing, or peptide mapping when the downstream use requires high confidence. For publication, QC release, or cloning design, validation should be planned early rather than added after reporting.
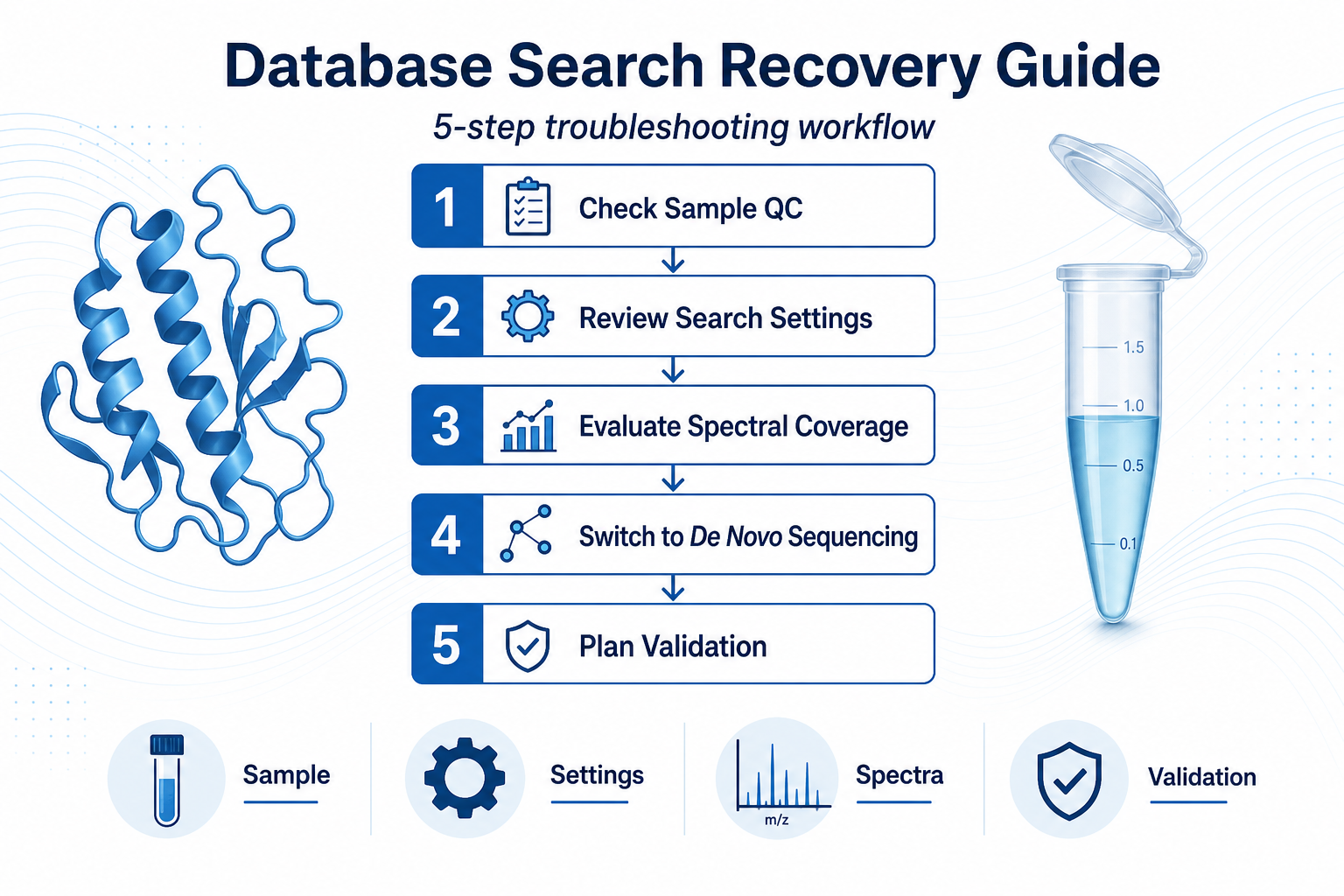
Figure 2. A structured recovery path reduces repeated failed searches and unnecessary delays.
Sample Requirements and Preparation Tips
Sample quality is often the difference between a successful de novo sequencing project and a repeat submission. The figure below summarizes common requirements and risk factors.
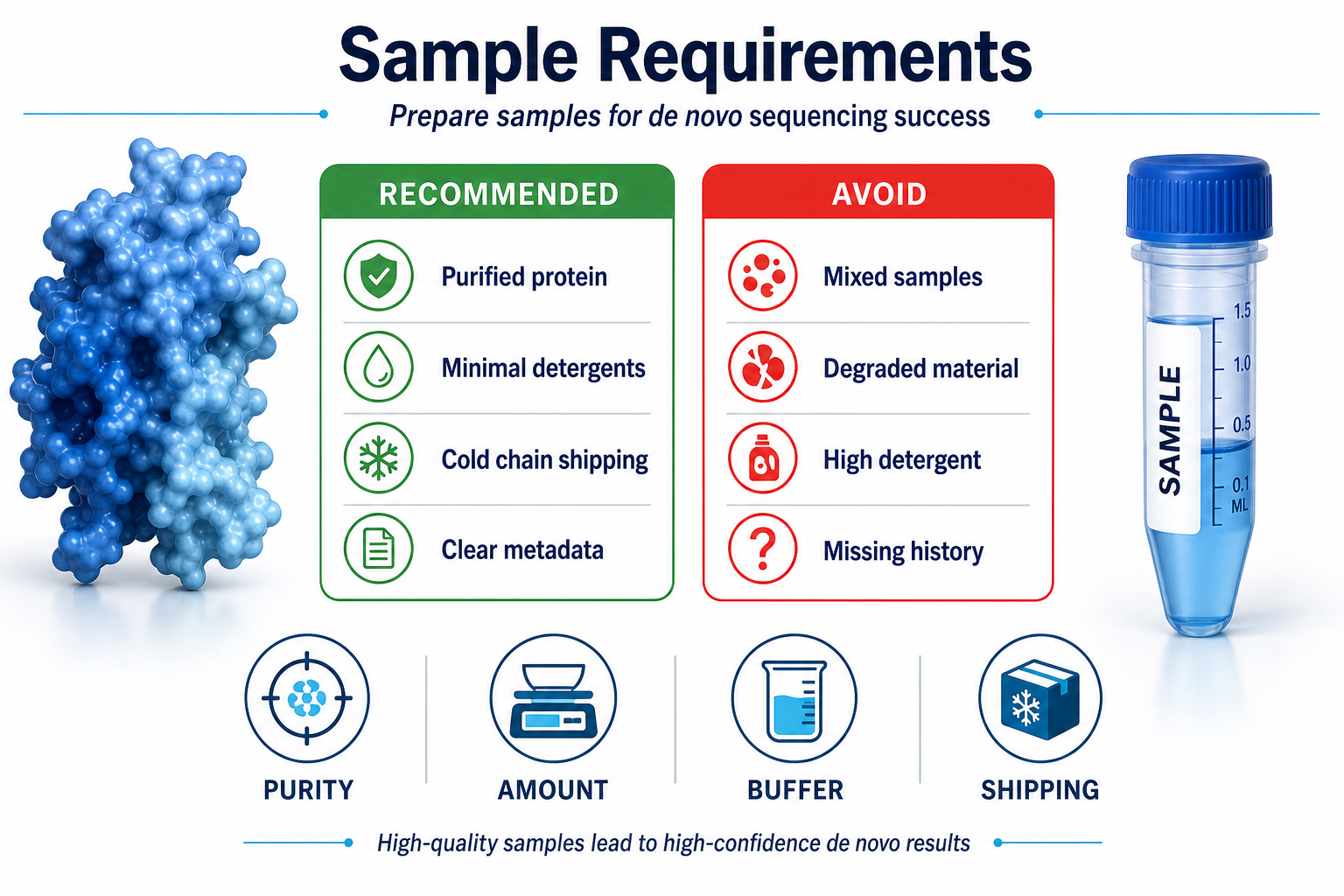
Figure 3. Feasibility review before sample submission reduces rework and shortens project timelines.
For peptide-level projects, teams may also consider when the target is a short peptide rather than a full protein.
Expected Results and Validation Methods
A successful recovery project should deliver more than a sequence string. Expected outputs may include:
Validation options depend on project goal:
Database-free sequencing can provide strong primary structure evidence, but validation should match the decision the data must support.
Key Cautions
For difficult samples, a combined strategy may be best. Database-free sequencing can recover unknown regions, while or can confirm regions once a reference is established.
Frequently Asked Questions
1. Should I rerun the same database search before trying database-free sequencing?
A parameter review is reasonable, but repeated searches against the same incomplete database rarely solve the core problem. If no reliable reference exists, de novo sequencing is usually the more direct option.
2. Can a pure-looking band still fail database search?
Yes. Purity alone does not guarantee a database match. A pure sample from an unannotated or proprietary source may still lack a valid reference entry.
3. How much sample is needed for database-free sequencing?
Requirements depend on protein size, purity, and complexity. A feasibility review is recommended before submission, especially for low-abundance or difficult samples.
4. Can database-free sequencing recover the full protein sequence?
In favorable cases, yes. Coverage depends on digestion efficiency, spectral quality, protein length, and sample complexity. Some projects recover complete sequence information, while others produce high-confidence partial coverage.
5. What should I do if only part of the sequence is recovered?
Use the recovered regions for cloning design, terminal checks, or targeted follow-up experiments. Partial sequence data can still move a project forward when the supported regions are clearly documented.
Conclusion
A failed database search is often a signal that the project needs database-free sequence analysis, better sample preparation, or both. Database-free sequencing provides a practical recovery route when reference sequences are missing, incorrect, or insufficient. By reviewing sample quality, search limitations, and validation needs before resubmitting material, research teams can avoid repeated delays and obtain sequence evidence that supports the next experimental decision.
When database-assisted identification cannot resolve sample identity, MtoZ Biolabs can plan a recovery workflow using , terminal analysis, or peptide mapping based on sample type and project goal. Contact the technical team to review failed search results, sample status, and path to usable sequence evidence.
How to order?

